Human Pose Estimation with Deep Learning
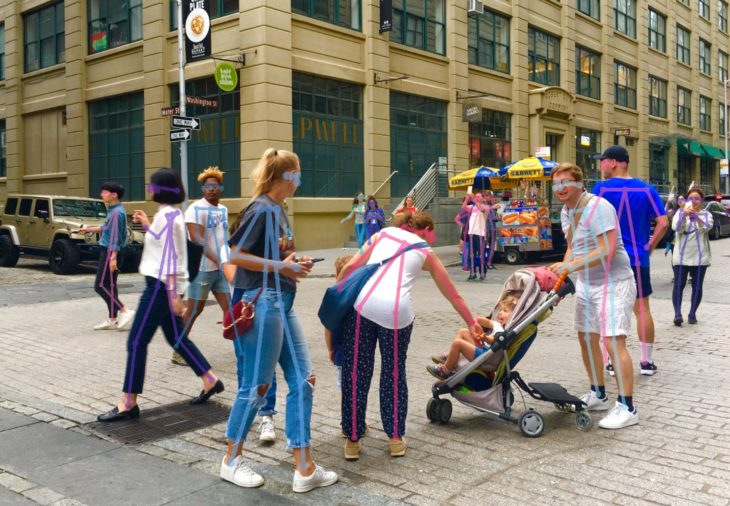
Human Pose Estimation is a Machine Learning task that uses computer vision techniques to identify the body posture of a person.
This article is part of our Human Pose Estimation Product.
You can find our related works on the following pages:
1- Pose Estimation on Nvidia Jetsons using OpenPifPaf
2- TinyPose; Galliot’s edge-device-friendly model for Pose Estimation
3- Data Labeling Methodology; A guide to the approaches, challenges, and tools for creating datasets.
This is going to be a set of articles in which we will review the various approaches for Human Pose Estimation with deep learning techniques. In this part, we introduce Pose Estimation, its applications, and different pipelines for human pose estimation. In the future parts, we will discuss the various techniques of Top-Down and Bottom-Up Approaches.
1. What is Human Pose Estimation
Human Pose Estimation is a Machine Learning task that uses Computer Vision techniques to identify the body posture of a person. Machine estimates the human body’s Key-Points (joints), such as shoulders, elbows, and wrists, in videos or images. Then it can indicate and track a person’s various postures by connecting the related points. (Fig.1)

2. Human Pose Estimation Applications
Pose estimation has a wide range of applications, such as occupancy analytics, sports video analytics, video games, animations, commercial real estate analytics, and workspace health and safety monitoring. For example, the “Microsoft Kinect” device uses pose estimation to identify the players’ movements and actions to control the game. After introducing Deep Learning to human pose estimation, it has made significant advancements. Many practical, real-life applications, such as pose estimation for human crowds, are possible thanks to the power of deep convolutional neural networks (CNNs). Nowadays, human pose estimation is used for physiotherapeutic evaluations and exercises in the healthcare sector.

3. Classical and Deep Learning Approaches to Human Pose Estimation
Great efforts have been made to enhance human pose estimation performance for real-life problems. In early works on articulated human pose estimation, classical approaches used a framework called “Pictorial Structures.” The “Pictorial Structure” models the spatial correlation of rigid body parts, usually using a tree-structured graphical model to predict the body joints’ location. For example, Matthias Dantone et al. have employed two-layered random forests as joint regressors to indicate joint locations (Fig. 2). However, the Tree models show a good result when the limbs are visible; they fail to capture the correlation between invisible and deformable body parts. Moreover, some hand-crafted features were applied in early works for human pose estimation. These features, such as edges, color histograms, contours, HOG (histogram of oriented gradients), etc., were used as the main building blocks of different classical models to determine the accurate locations of body parts.
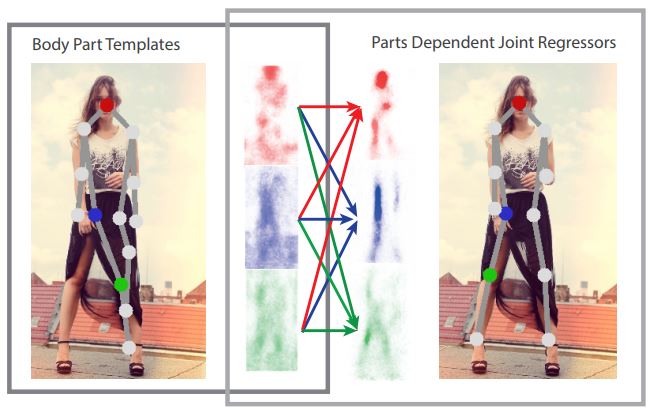
Classical methods faced several problems, such as poor generalization and inaccurate body parts detection. To solve the limitations and problems in classical approaches, scientists utilized Deep Learning in human pose estimation. Deep Learning, specifically Convolutional Neural Networks (CNNs), remarkably improved previous methods and helped solve the challenges. Currently, most of the research in this field and use cases of human pose estimation are based on deep learning structures.
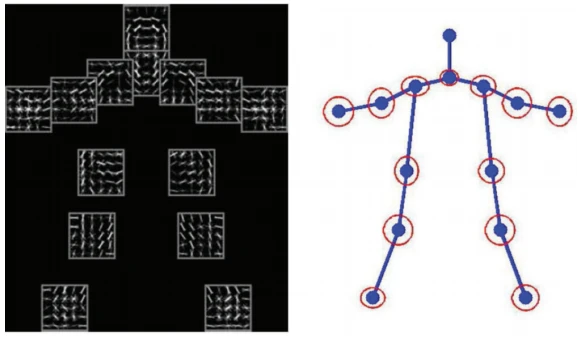
4. Single-Person and Multi-Person Pose Estimation
Generally, based on the number of people being tracked, we can classify human pose estimation into Single-Person (SPPE) and Multi-Person pose estimation. Single-person pose estimation is much easier for estimating a single human’s posture in an image than multi-person pose estimation, which identifies and evaluates the pose of all unknown numbers of people present in a given image or video (Figure 5). Since some real-world applications of human pose estimation fall into crowded environments with several individuals present, SPPE has some constraints for these applications. Thus we require a more elaborated pipeline to overcome the challenges of multi-person pose estimation.

4.1. Single-Person Pose Estimation (SPPE)
As mentioned earlier, SPPEs are applicable for estimating humans’ posture in an image or a video when there is only one person in the image, or the position of the human is somehow given before the estimation (e.g., using a bounding box). The single-person method finds the key body points’ positions using an RGB image. The model has to indicate the key points either by regressing key points’ locations directly (KeyPoint Regression) or using a more sophisticated approach such as Heatmap Regression.
KeyPoint Regression:
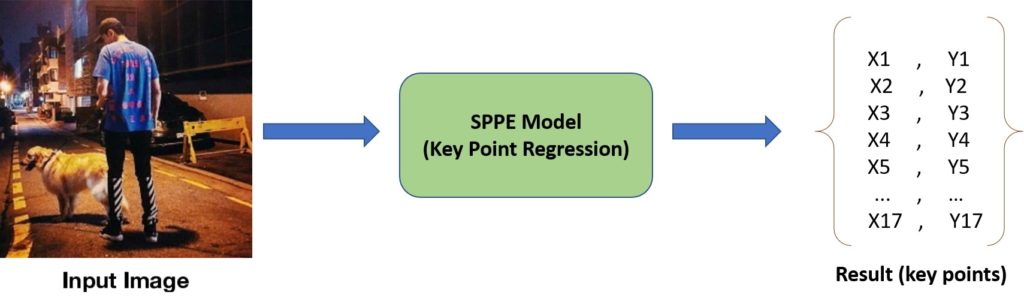
In this method, the model regresses the key body points directly from the feature maps; hence, it is called Direct Regression in some references. If you want to estimate 17 key points for an individual using this method, the model’s output will be a 17 by 2 vector containing each predicted key point’s X and Y coordinates (Figure 6). Many different models, such as Carreira et al., Sun et al., and Luvizon et al., are proposed based on the keypoint regression approach to enhance its performance in finding the exact points. To explain this approach’s main challenge, imagine an instance in which the model predicts a particular key-point location with a variance of one or two pixels from the ground truth. This slight variance in the model’s prediction causes an error that disturbs the training process and prevents the model’s convergence into an optimum solution; however, such a small difference in the estimation is neglectable in many applications. Therefore, training a model to directly identify the exact point increases the problem’s complexity and sensitivity and causes instability in training the model.
Heat Map Regression:
To solve the sensitivity and instability, heat map regression was implemented by researchers as an alternative approach. Despite the previous method that we used to directly detect the exact location of each key point, in this framework, we estimate the probability of the existence of a key point in each pixel of the image. We demonstrate more probable keypoint zones using a heat map. Implementing this method disregards slight differences in key-point prediction and lets the model train more relaxed.
There are two challenges facing heat map regression. First, the key point extraction uses heat maps (decoding problem), which have solutions like choosing the peak or the average of each heat map as a key-point location. The other problem is creating a Ground-truth; Since the model’s output is in the form of a heatmap, we need to transform our Ground-Truth (which consists of keypoint coordinates) into the same format (encoding problem). For example, we can fit a Gaussian distribution centered around the ground-truth key points with a small variance.

4.2. Multi-Person Pose Estimation
Compared to the single-person pose estimation, multi-person is more difficult because neither the position nor the number of individuals is given to the model. There are two main pipelines in multi-person approaches; Top-Down & Bottom-Up. The top-down approach is more comfortable to employ than the bottom-up approach, as the top-down is somehow just an expansion of SPPE. There are a few main challenges in each pipeline, i.e., if we choose the top-down approach, we should solve the KeyPoint estimation and Human detection problem. In contrast, we need to face the KeyPoint grouping challenge by choosing the bottom-up approach.
Top-Down Approaches:
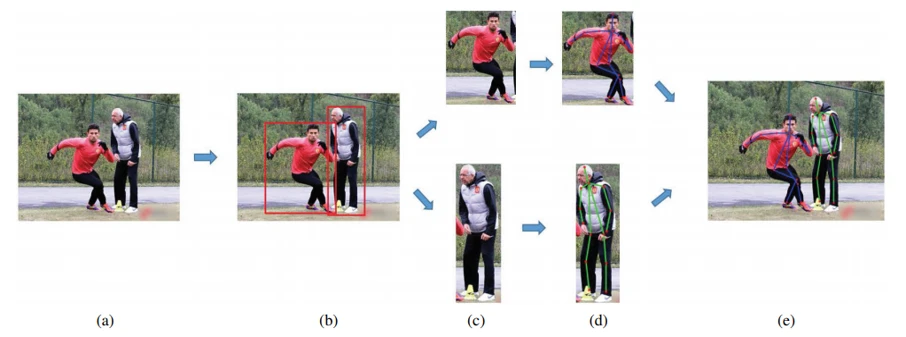
As shown in Fig. 8, the first step in the top-down approach is detecting all individuals in a given image using a human detector module (bounding box object detector). After indicating bounding boxes for each person available in the image, every individual is cropped and resized. At this point, we break the problem of multi-person pose estimation into a Single-Person pose estimation (SPPE) for each cropped image. Later a single-person approach is performed on each individual to detect the key points. Finally, a post-processing step, e.g., Non-Maximum Suppression (NMS), will apply to illustrate the multi-person pose detection result.
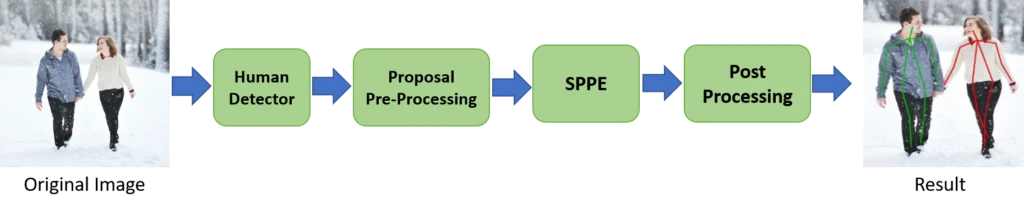
Top-down approaches are more straightforward because of two main reasons. On the one hand, it is the same SPPE problem after the detection step, and on the other hand, we can use one of the off-the-shelf detectors, such as Faster R-CNN, YOLO, or SSD. However, there is a big problem in these approaches called; “early commitment,” which means If the human detector fails to detect individuals accurately in an image, it will disrupt the whole process, and the recovery is impossible. The Top-down approach is also sensitive to multiple individuals near each other (overlapping and occlusion) and performs poorly. Because the occlusions of people in the image can prevent the human detector from indicating bounding boxes for individuals behind each other. Also, overlapping people in a single detected bounding box might change the state of the problem from a single person to a multi-person. Additionally, as the number of people increases in an image, the computational cost rises because, for each human detection, the model has to run a single-person pose estimator.
Bottom-Up Approaches:
Despite top-down approaches, bottom-up methods start by detecting all key points (body parts) in an instance-agnostic manner and then associating key points to build a human instance (Fig. 10). Since these approaches do not need to estimate each person’s pose separately, the computational costs are relatively lower than top-down methods. Early commitment is not an issue for this method. Bottom-up approaches have challenges connecting the key points and building the human instances for crowd images where there is a large overlap between people; however, this problem is more severe in the top-down pipeline. Also, as the number of instances increases, the association module computational cost rises.


5. Human Pose Estimation DataSets
While building a universal dataset for diverse human postures and different estimation approaches is difficult, there are a few popular human pose datasets in this field. These datasets are proposed with different numbers of annotated key points and types (upper body or full body).
The most popular publicly available datasets used for deep learning methods are; COCO, MPII, AI Challenger, and FLIC. Earlier datasets, such as Buffy or VOC, contain a small number of images with simple backgrounds, hence not suitable for deep learning approaches.

Amongst these datasets, the most appealing one for multi-person models, COCO (Common Objects in Context), contains more than 200’000 images in which 250’000 individuals are labeled with a 17 key-point format. Another commonly used dataset MPII (Max Planck Institute for Informatics), consists of 25’000 images gathered from youtube videos, from which 40’000 individuals are annotated with 16 body joints as key points.
6. Conclusion
This article (part 1) presented a brief overview of human pose estimation, classical and deep-learning approaches for pose estimation, and the challenges facing each method. Also, various real-world applications of pose estimation are introduced.
The human pose estimation pipeline is classified based on the number of people available in an image. In the end, some of the most popular datasets for deep learning multi-person methods are introduced.
In the following parts, we will discuss the novel models employed on Top-Down and Bottom-Up frameworks in single or multi-person cases.
Pose Estimation with DeepLearning Recap:
1- What is Human pose Estimation?
Generally, Pose Estimation is a Deep Learning task that detects and illustrates the orientation and position of the parts of an object using Computer Vision techniques. When we use these techniques to indicate the various body limbs and estimate the postures of a person in an image or video, it is called Human Pose Estimation.
2- What are some real-world applications of Human Pose estimation?
It has a great variety of use cases in health care, surveillance measures, sports, etc. that some are currently being applied to real-world settings. Pose estimation is already changing the chronic diseases (physiotherapy) industry by improving patient care services. It has great importance in video games and animation production. Sports video analytics, Occupancy analytics, commercial real estate analytics, and workspace health and safety monitoring are other applications of human pose estimation.
3- What is the difference between Joint (Key Point) Regression and Heatmap Regression?
The main difference between these two solutions is how they estimate the body key joints. In Key Point Regression (Direct Regression), the model directly indicates the body joints and its output is the key point coordinates. But, Heatmap Regression estimates the probability of the existence of a key point in each pixel of the image. So, the model output is a heatmap indicating these probabilities. While Heatmap Regression has some extra steps, such as decoding and encoding, it is more robust and less sensitive than Key Point Regression.
4- How does Multi-Person Pose Estimation work?
There are two main pipelines in multi-person approaches; Top-Down & Bottom-Up.
The core of the Top-Down approach is similar to a single-person pose estimator. It first uses a Human Detector to indicate and crop each individual in an image. Then, it implements a Single Person Pose Estimator for each person bounding box. Finally, it puts all the people back in one frame to show the result. On the other hand, Bottom-up estimates all key points in an image first and then connects the key points of each individual.
Please feel free to write your thoughts in the comment section and help us improve and update the post. For further questions, contact us or send emails via hello@galliot.us.
You can subscribe to our newsletter to learn about this article’s next part’s publication.
Leave us a comment
Comments
Get Started
Have a question? Send us a message and we will respond as soon as possible.
This is the right blog for anyone who wants to find out about this topic. You realize so much its almost hard to argue with you (not that I actually would want…HaHa). You definitely put a new spin on a topic thats been written about for years. Great stuff, just great!