Serverless: A Paradigm Shift or Overhyped Trend in Infrastructure?

In the past, people fetched water from wells and prepared it for drinking. Now, with tap water systems, we pay for what we use. In terms of technology, can serverless architecture be like tap water?
Is serverless architecture a game-changer or just another fad? This new capability presents both challenges and opportunities. Read on to learn more about serverless risks and opportunities.
💡 Don’t miss out on our article comparing Cloud and Edge Computing! It discusses the benefits and drawbacks of both technologies and includes an example of effectively using a hybrid cloud-edge computing system for machine learning. Read more.
Intro
In the past month, software engineers on Twitter have been engaged in intense discussions about a potential shift from serverless architecture and microservices to a monolithic architecture and dedicated virtual machines (VMs), such as EC2 instances. These discussions were sparked by an article released by the Amazon Prime engineering team. The article detailed a noteworthy case study where the Prime Video team at Amazon abandoned their serverless microservices approach and replaced it with a monolithic architecture instead. This strategic move resulted in an astounding 90% reduction in operating costs and simplified their system significantly. This article shook the software industry, contradicting the recent trend of utilizing serverless architecture to enable rapid scalability and lower development and maintenance costs.
Consequently, there have been numerous debates on this topic on Twitter throughout the last month. In this article, we will introduce the concept of serverless, explore its advantages and disadvantages, examine its use cases, and discuss the available services for its implementation. Once we understand the concept, we will delve further into the Serveless or No-Serveless debate, providing more in-depth analysis.
Evolution of Deployment
The history of deployment in software development and operation has been marked by a steady progression toward greater efficiency, scalability, and convenience until it has led to the emergence of serverless architecture.
The early days of computing required developers to have their own server hardware and install the necessary software on it. This process was time-consuming and expensive and limited the ability of developers to quickly iterate on their code. However, as the internet grew, companies started to offer server hosting services, which allowed developers to deploy their applications on remote servers, reducing the burden of maintaining server hardware. However, it still required developers to manage the operating system and other software running on the server.
The advent of virtualization technology, such as virtual machines (VMs), allowed developers to run multiple applications on a single server, with each application running in its isolated environment. This technology made it easier to manage multiple applications on a single server and provided a way to move applications between servers easily.
Cloud Computing as a Solution
However, even with virtualization’s benefits, managing servers and infrastructure still requires significant time and resources. Cloud computing emerged as a solution to this problem. It allows developers to provision and manage servers and other resources “on demand” without worrying about the underlying hardware. Still, even with cloud computing, developers often had to hand off their code to an infrastructure engineer or operations team to deploy the application, resulting in several drawbacks.
Traditional Deployment Challenges
The traditional approach to deployment slowed down the development process, as developers had to wait for the operations team to deploy their code. Additionally, it often resulted in silos between the development and operations teams, each working in isolation from one another.
The Emergence of Serverless Architecture
The serverless architecture seeks to solve these problems by allowing developers to focus solely on their code while leaving the underlying infrastructure management to the cloud provider. This approach not only speeds up development but also encourages collaboration between development and operations teams, as both are working towards a common goal of delivering reliable and scalable applications.
With serverless architecture, developers don’t need to worry about providing or managing servers at all. Instead, they simply upload their code to a cloud provider, which automatically manages the infrastructure and scales the application as needed. This approach allows for even greater flexibility, efficiency, and cost savings, as developers only pay for the resources they actually use.
💡 Headache of Using Patch Management
Imagine you were a software developer in a company in the 2000s with several services running on multiple servers. Each server had a different operating system, and keeping them up to date was a real headache. Whenever a new security patch or bug fix was released, you had to install it on each server manually. This was time-consuming and error-prone, taking you away from your primary job of writing code and developing new features. Despite your best efforts, you sometimes missed updates or applied them incorrectly, which led to software errors and downtime. Customers were unhappy, and your bosses were even unhappier. Over time, the problem only got worse. As more servers were added to the company’s infrastructure, you found it increasingly challenging to keep track of all the updates and patches that needed to be applied.
To address this challenge, you turned to patch management software, which helped automate the process of applying software updates. The updates included security fixes, bug fixes, and other updates that improved the performance and reliability of the software. Fortunately, with the advent of serverless computing, developers no longer need to worry about applying updates with patch management software. Service providers handle all the necessary OS updates and maintenance tasks, eliminating the need for patch management software. This allows developers to focus on writing code and building new applications without the headaches of manual updates or the complexity of patch management. Serverless computing seamlessly integrates updates, and developers can enjoy a more streamlined and hassle-free experience.

What is Serverless? (How it works?)
Serverless computing is a cloud computing model that allows developers to build and run applications without worrying about the underlying infrastructure. With serverless computing, the cloud provider manages the servers, networking, and storage required to run the application while the developer focuses solely on writing code.
In a serverless architecture, the application is broken down into small, independent functions that can respond to specific events, such as an HTTP request, a message in a queue, or a file upload. These functions are typically short-lived, stateless, and scalable, meaning they can handle a large number of requests without requiring any additional configuration or management.
When an event occurs, the cloud provider automatically provides the necessary resources and executes the appropriate function to handle the event. The function runs in a container or virtual machine isolated from other functions, ensuring each has its own dedicated resources.
After the function completes, the container or virtual machine is destroyed, and the resources are released back to the cloud provider. This means that you only pay for the resources used by each function rather than the entire infrastructure all the time.
Serverless computing can offer several benefits, including faster development cycles, reduced infrastructure costs, and increased scalability and flexibility. However, it may also come with some limitations, such as reduced control over the underlying infrastructure and potential vendor lock-in. We will investigate these pros and cons throughout the article.
Serverless Use Cases
1- Web development
Suppose you’re building an e-commerce website that allows users to browse and purchase products. In that case, you must create several APIs that interact with your database to retrieve and update product information.
Traditionally, this required providing and managing servers to handle incoming API requests and process data. However, the serverless architecture allows you to write your API functions as serverless functions, which are then deployed to a cloud provider.
To accomplish this, you would write your API code using a serverless framework or platform, such as AWS Lambda or Google Cloud Functions. You would define your API endpoints and the corresponding functions that will be called when those endpoints are hit. The cloud provider will automatically handle the scaling and resource allocation needed to handle incoming traffic, ensuring your API remains fast and responsive for all users.
Using serverless architecture for APIs also saves costs because you only pay for the resources you use. This can be particularly advantageous if your website experiences fluctuating traffic throughout the day, as you can avoid over-provisioning servers during periods of low traffic.
2- CI/CD Pipelines
Continuous Integration and Continuous Deployment (CI/CD) is a popular practice in software development that involves regularly merging code changes into a shared repository and automatically building, testing, and deploying the application. Previously, you had to set up and manage your own build and deployment servers to handle the CI/CD pipeline.
With serverless architecture, however, you can build your CI/CD pipeline using serverless functions that are automatically triggered by events. For example, when you push code changes to a Git repository, you can trigger a serverless function that automatically builds and tests the application. If the tests pass, another function can be triggered that deploys the new code to your production environment.
3- ML Applications
Suppose you have a machine learning model that needs to perform real-time inferencing on streaming data. For example, you want to deploy a machine translation application. Traditionally, you would need to set up and manage GPU servers to handle the inference requests, scalability, and load management of the servers, which can be time-consuming and expensive. On the other hand, your expensive servers were most of the time idle, so you were charged for idle servers.
Serverless architecture allows you to use serverless functions to perform ML inferencing which provides several benefits. Firstly, it allows for cost savings, as you only pay for the resources you actually use. Additionally, serverless architecture simplifies the deployment process, as you don’t need to worry about setting up and managing servers. This lets you focus on the ML logic rather than the underlying infrastructure.
💡 Example: Serverless Use-Case For Large Language Models (LLM)
Imagine you are a company that provides natural language processing (NLP) services to your clients. One of your clients wants to use a large language model (LLM) to perform sentiment analysis on their social media data. However, deploying such a model on local servers can be challenging due to their resource-intensive memory and computation requirements.
To address this challenge, you suggest using serverless computing to deploy and host the LLM. You start by selecting a serverless platform that supports Python and TensorFlow, the technology stack required to run the LLM.
Next, you package the LLM model and its dependencies into a container image and upload it to a container registry. Then, you create a serverless function that loads the LLM model from the container image and exposes an API endpoint for the client.
When a user submits a request to the API endpoint with a social media post, the serverless function receives the request, applies the LLM model to the text, and returns the sentiment analysis results to the client. The serverless platform automatically scales the resources based on the incoming traffic, ensuring the service is always available and responsive.
By using serverless computing to deploy the LLM, the client can avoid the cost and complexity of managing the infrastructure themselves. They can simply consume the NLP service through an API without worrying about the underlying technology or maintenance tasks. This allows the client to focus on their core business objectives while benefiting from the power of a large language model.
Serverless Architecture; Pros and Cons
Serverless Advantages
Cost: One of the key advantages of serverless architecture is its ability to reduce operational costs significantly. This is achieved by eliminating businesses needing to maintain and manage their servers, which can be expensive and time-consuming. With serverless, companies only pay for their cloud-based computing time rather than constantly running and maintaining servers regardless of demand. This pay-per-use model can result in substantial savings for businesses, as they only pay for the resources their application requires.
Elasticity: Another critical benefit of serverless architecture is its ability to dynamically adjust to demand changes, commonly referred to as elasticity. With serverless, businesses no longer need to worry about over- or under-providing their resources, as the infrastructure automatically scales up or down to meet the current workload. This means that if there’s a sudden spike in traffic, the serverless architecture can quickly and seamlessly adjust to handle the increased load. Contrariwise, the infrastructure can automatically scale down if demand drops to reduce costs.
Who builds the code runs it: The “who builds, runs” principle in serverless architecture allows developers to deploy their code directly to production without needing hand-offs with DevOps engineers. This is made possible by serverless platforms’ ease of use and simplicity. It enables developers to focus on building and testing their code rather than worrying about infrastructure and operations. Since developers are intimately familiar with the code they have written, they are often best equipped to debug and troubleshoot issues that arise in production—resulting in faster resolution times and increased uptime for applications. At the same time, DevOps engineers can focus on managing the underlying infrastructure and providing support for the development team rather than being responsible for deploying and maintaining every single piece of code. By allowing developers to deploy their code and take ownership of the entire development lifecycle, serverless architecture can promote collaboration, reduce delays, and increase the overall agility and effectiveness of the development process.
Serverless Disadvantages
Build-up time: One potential disadvantage of serverless architecture is the build time of serverless applications. Because serverless functions are only executed in response to a trigger, such as an HTTP request or a message from a queue, they may need to be started up each time they are triggered. This startup delay can be significant for applications with long build times and impact application performance. Additionally, the process of packaging and deploying serverless applications can be more complex than deploying traditional ones. This may require additional time and effort. While some serverless platforms offer pre-warming features that can help reduce startup delays, this can come at an additional cost. As a result, businesses using serverless architectures may need to carefully consider the build time of their applications and ensure that it is optimized for their specific use case.
Not suitable for high-performance computing: Serverless architecture may not be the best choice for high-performance computing (HPC) workloads due to its inherent limitations. Serverless functions are designed to execute quickly and then terminate. So they may not be well-suited for long-running or compute-intensive tasks that require a significant amount of resources. Additionally, serverless architectures may have limitations on the amount of memory, CPU, and other resources allocated to each function, limiting their ability to handle high-performance computing workloads. While some serverless platforms offer support for HPC workloads, these may come at an additional cost or require significant customization. As a result, businesses considering serverless architecture for HPC workloads should carefully evaluate the platform’s capabilities and ensure that it is optimized for their specific needs.
Limitations in debugging, profiling, and monitoring: Debugging, profiling, and monitoring serverless applications can be challenging due to the distributed nature of the architecture. As serverless functions are typically composed of multiple smaller functions and services, it can be challenging to trace issues and identify performance bottlenecks. Further, serverless architectures may have limited visibility into the underlying infrastructure and may not provide access to traditional debugging and monitoring tools. This can make it hard to identify and resolve issues in real-time, impacting application performance and availability. To address this challenge, businesses using serverless architecture may need to invest in specialized monitoring and debugging tools designed to work with these architectures. Alternatively, they may need to modify their development processes and code to include additional logging and error-handling functionality.
Privacy and Security: Privacy can be a concern when using serverless architecture, particularly if the serverless functions are processing sensitive data. Because serverless functions are typically executed in a shared environment, there is a risk of data leakage or cross-function contamination if proper isolation and access controls are not in place. Also, as we said, serverless functions are often triggered by events from external sources. Thus there is a risk of unauthorized access or injection of malicious code. To address these privacy concerns, businesses using serverless architecture should ensure their code is designed with security in mind and follow best practices for securing their serverless environments. This may include implementing access controls and authentication mechanisms, encrypting sensitive data, and monitoring serverless functions for suspicious activity. Additionally, businesses should carefully evaluate their serverless providers and ensure that they have appropriate security measures to protect their data.
Different Providers of Serverless
AWS Lambda
AWS Lambda is a serverless computing service provided by Amazon Web Services (AWS) that allows you to run code without having to provision or manage servers. With AWS Lambda, you can create functions in multiple programming languages such as Node.js, Python, Java, C#, and Go, and execute them in response to various triggers, such as changes to data in an Amazon S3 bucket or a new message in an Amazon Simple Notification Service (SNS) topic.
One of the main benefits of AWS Lambda is its scalability. Since you don’t need to manage servers, you don’t have to worry about provisioning additional resources as your application usage grows. AWS Lambda automatically scales your application by creating new instances of your function in response to increased demand and then removes them when demand decreases. This makes it a highly cost-effective option for applications with variable workloads.
AWS Fargate
AWS Fargate is a serverless compute engine for containers offered by Amazon Web Services (AWS) that enables developers to run Docker containers serverless without needing to manage the underlying infrastructure. With Fargate, developers can focus on writing containerized applications while AWS takes care of the rest, including provisioning, scaling, and managing the underlying infrastructure. Fargate allows you to define the desired resources for your containerized application, such as CPU and memory, and then automatically scales the resources up or down based on the application’s workload. It seamlessly integrates with other container services in AWS, like ECS, ECR, and EKR.
AWS Fargate also provides a secure and compliant environment for running containerized applications. Fargate integrates with other AWS security services, such as AWS Identity and Access Management (IAM), AWS Key Management Service (KMS), and Amazon Virtual Private Cloud (VPC), to provide a comprehensive security model that meets industry-specific compliance requirements.
💡 Comparing AWS Lambda with AWS Fargate
While AWS Fargate and AWS Lambda are both serverless computing services offered by AWS, they have some fundamental differences in their approach and functionality. One of the main differences is the type of workload they support. AWS Lambda is a Function-as-a-Service (FaaS) offering that allows you to run individual functions in response to events. In contrast, AWS Fargate is a container-as-a-service that lets you run long-running containerized applications. This means that AWS Lambda is best suited for small and stateless event-driven functions. In contrast, AWS Fargate is better suited for larger, stateful applications that require persistent resources.
Another difference between the two services is their scaling behavior. AWS Lambda automatically scales based on the number of events it receives, whereas AWS Fargate scales based on the application’s resource requirements. Meaning that AWS Lambda is better suited for workloads with unpredictable or bursty traffic, while AWS Fargate is better suited for workloads with steady or predictable traffic.
Additionally, AWS Fargate offers more control over the resources allocated to the application, with the ability to specify the exact amount of CPU and memory required. In contrast, AWS Lambda has limited control over the resources allocated to each function, with the amount of CPU and memory being automatically determined by AWS based on the size of the function.
In terms of pricing, both AWS Fargate and AWS Lambda offer a pay-as-you-go pricing model with no upfront costs or long-term commitments. However, AWS Fargate typically has higher costs than AWS Lambda because it provides more control over the underlying infrastructure.
Google Cloud Functions
Google Cloud Functions is a serverless compute service offered by Google Cloud Platform (GCP) that enables developers to write and execute event-driven code in response to various triggers, such as changes to data in Google Cloud Storage or new messages in Google Cloud Pub/Sub. Unlike traditional server-based architectures, Cloud Functions abstract the underlying infrastructure, allowing developers to focus on writing code rather than managing servers. Like what we mentioned for AWS Lambda Functions, Google Cloud Functions also has the scalability feature and integration with other GCP services. Google Cloud Functions provides a built-in debugger, which makes it easier to troubleshoot and fix issues with your functions. The debugger allows you to set breakpoints, inspect variables, and step through code in real-time, making it easier to identify and resolve bugs.
Azure Functions
This Microsoft Azure serverless computing service allows you to run event-driven code without the need to provision or manage infrastructure. With Azure Functions, you can build highly scalable and flexible architectures that can respond to changing business needs while only paying for the resources used by your code.
Azure Functions supports multiple programming languages, including C#, Java, JavaScript, Python, and PowerShell, making building applications in your preferred language easy. To simplify development and deployment, you can also leverage pre-built templates and integrations with other Azure services, such as Azure Event Grid, Azure Service Bus, and Azure Blob Storage.
Azure Functions provides a variety of trigger types that can automatically execute your code in response to events, such as HTTP requests, messages in a queue, or changes in a storage account. You can also create custom triggers using Azure Event Grid, allowing you to trigger your code based on events from other Azure services or third-party sources. Azure Functions offers a flexible pricing model with a consumption-based plan that allows you to pay only for the resources used by your code. This model is ideal for unpredictable or bursty traffic workloads, as it automatically scales up and down based on the workload. Azure Functions also offers a premium plan that provides dedicated resources for your code, which can provide higher performance and lower latency for mission-critical workloads.
Integration With Other Services
When it comes to harnessing the full potential of serverless architecture, the seamless integration of serverless functions with various services is a critical aspect. By bridging the gap between serverless and essential components like databases, messaging services, and more, developers can unlock new levels of functionality and flexibility. In this section, we will delve into the intricacies of integrating serverless functions with different services, exploring techniques that enable efficient communication, data storage, event-driven triggers, and more.
Database
Serverless services can be integrated with databases in various ways, depending on the specific database and serverless service being used. One common approach is to use a managed database service, such as Amazon RDS, Azure Cosmos DB, or Google Cloud SQL. These services allow you to run a fully managed database instance in the cloud, with automatic scaling, backup, and maintenance, without the need to manage the underlying infrastructure. Serverless functions can then interact with the database through APIs or drivers provided by the database service, using standard database protocols such as SQL or NoSQL.
Another approach is to use a serverless data platform, such as Amazon DynamoDB, Azure Cosmos DB, or Google Cloud Firestore. These platforms provide a fully managed, serverless database that can scale automatically to handle any amount of data and traffic. Serverless functions can then access the data directly through APIs or SDKs provided by the platform without the need to manage the database infrastructure.
In addition to these options, serverless functions can also interact with databases using standard APIs and protocols, such as RESTful APIs, GraphQL, or WebSockets. This can allow you to integrate with any database that provides a compatible API, whether a managed database service or a self-hosted database.
Massaging
Another standard approach to integrate serverless here is using a managed messaging service, such as Amazon Simple Queue Service (SQS), Azure Service Bus, or Google Cloud Pub/Sub. Using these services, you can send and receive messages between different components of your application with automatic scaling, high availability, and message durability. Serverless functions can then interact with the messaging service through APIs or SDKs provided by the messaging service, using standard messaging protocols such as JMS, AMQP, or MQTT.
Another approach is using a serverless compute platform with built-in messaging capabilities, such as AWS Lambda with Amazon EventBridge or Azure Functions with Azure Event Grid. These services allow you to trigger functions in response to events from different sources, including messaging systems, with automatic scaling and high availability. Serverless functions can then access the message payload and metadata directly in their event data without the need to manage the messaging infrastructure.
Routing
You can use services like AWS API Gateway or Azure API Management to route messages to serverless functions. These services provide a way to expose a RESTful API or other types of endpoints for your application. They can route incoming requests to serverless functions based on the request path, HTTP method, headers, or other criteria.
For example, you could use AWS API Gateway to expose a RESTful API for your application, with different endpoints for different functionality. You could then configure API Gateway to route requests to other AWS Lambda functions based on the endpoint path or HTTP method. When API Gateway receives a request, it can transform it into a format that the target function can understand, such as a JSON payload.
Similarly, Azure API Management can expose APIs for your application, with the ability to route requests to Azure Functions based on various criteria. Azure Functions can also be integrated directly with Azure Event Grid, which can route events to different functions based on event type or other criteria.
Overall, routing messages to serverless functions through a service like API Gateway or API Management can provide a powerful way to build scalable, event-driven architectures that can respond to incoming requests or events in real-time.
Monoliths Are Not Dinosaurs
After understanding the concept and workings of serverless architecture, let’s revisit the debate surrounding Amazon Prime’s architectural shift. Initially, Amazon Prime relied on serverless components like AWS Step Functions and AWS Lambda. However, they encountered limitations in scaling and faced high costs due to state transitions, and excessive Tier-1 calls to the S3 bucket for video frame storage. To address these challenges, the team opted to restructure its infrastructure by transitioning from a distributed microservices approach to a monolithic application. This allowed them to eliminate the need for the S3 bucket as an intermediate storage for video frames and implement internal orchestration within a single instance using Amazon EC2 and Amazon ECS.
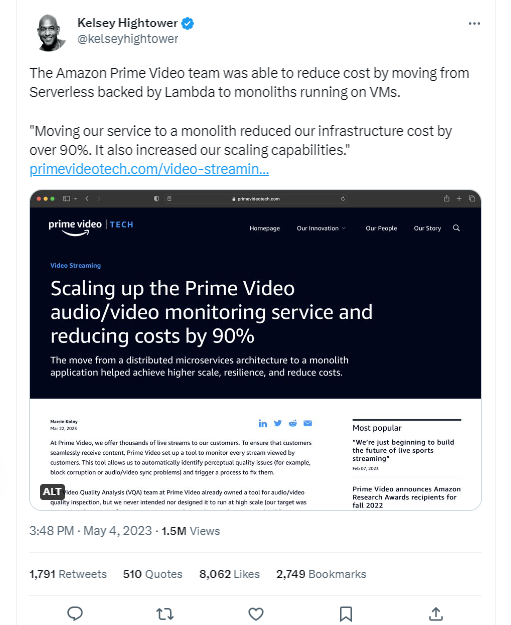
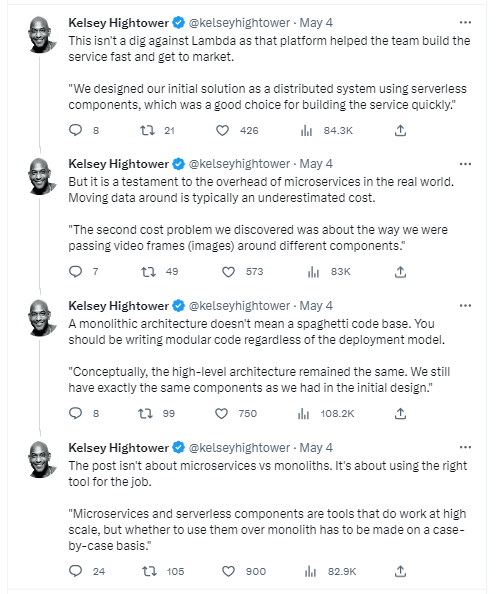
This case study highlights the importance of considering the suitability of microservices and serverless components versus a monolith on a case-by-case basis. While microservices and serverless architecture can function effectively at large scales, Amazon Prime Video’s decision to switch to a monolithic architecture resulted in significant cost savings and improved scalability. Kelsey Hightower, a prominent figure on Twitter, shared their insights on the matter.
In summary, the debate emphasizes that the choice between serverless and monolithic architecture should be based on each project’s specific requirements and circumstances. Amazon Prime Video’s experience demonstrates that a shift to a monolithic approach can deliver notable cost reduction and scalability benefits. Here is some explanation from Kelsey Hightower on Twitter.
Following the Amazon Prime case study, doubts arose regarding whether serverless architecture was an overrated concept in software engineering and if the hype surrounding it was unfounded. Subsequently, Werner Vogels, the CTO of AWS, contributed to the discussion with a tweet and a blog post of his own.
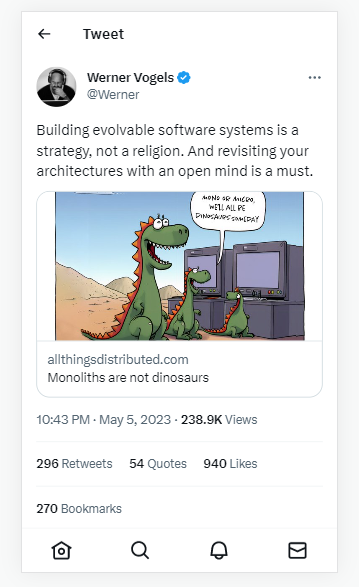
The consensus reached at the end of this debate was the importance of recognizing that software architecture does not have a universal solution. It is crucial to approach each situation with an open mind and select the most suitable approach.
Conclusion
In conclusion, this article has introduced serverless architecture as the cutting-edge approach to software deployment in the modern era. We explored its advantages and disadvantages, delving into the realm of renowned serverless providers and uncovering common industry use cases. By embracing serverless, developers can leverage its numerous benefits, including scalability, cost-efficiency, and reduced operational overhead. As we move forward, it is evident that serverless architecture will continue to revolutionize the way applications are built, empowering developers to focus on innovation and delivering exceptional user experiences. With this newfound understanding, you are well-equipped to embark on your serverless journey and unlock the boundless possibilities of this transformative paradigm.
While Serverless architecture offers numerous advantages, the Amazon Prime use case demonstrated that it is not a universally applicable solution. Therefore, it becomes the responsibility of engineers to identify the unique constraints and requirements of each problem and select the most appropriate solution accordingly.
We’re passionate about empowering our clients through seamless technical solutions. Let us be your trusted partner in transforming your serverless architecture. Reach out today to explore how we can elevate your development journey. Contact us via the form or email us at hello@galliot.us.
Get Started
Have a question? Send us a message and we will respond as soon as possible.
Leave us a comment