Cloud Vs. Edge Computing: An Example For Building Practical AI Apps

Walking on the edge, over the clouds
Here we provide an example to describe how we can combine the capabilities of Cloud and Edge Computing to create a practical machine learning application.
💡 Creating robust Deep Learning applications requires building good datasets.
Read about data labeling challenges and solutions for creating high-quality labeled data.
Also, visit our Edge Deep Learning article for the advantages and applications of the edge in the industry.
Contact us for Software Consulting and Development.
1. Introduction
Around 10-15 years ago, companies had to spend lots of resources to maintain infrastructure and keep their operations running. So, the internet had to go through a transformation to answer the growing demands in the IT and software development industry. The advent and utilization of cloud technology have changed the game. Cloud computing made processes more straightforward and efficient for businesses.
Nowadays, companies of every size are realizing the benefits of cloud technology and moving toward the cloud gradually. Artificial intelligence is not exempt from this transition. AI uses clouds as well as other software applications such as web development, streamlining the development and deployment of its applications.
Surely, cloud computing has helped us design AI applications faster and simpler. But it might struggle to carry on for applications that require real-time inferencing. Here enters edge computing to address these problems using the on-device processing concept.
Here we talk about the backgrounds of both cloud and edge AI. Reading our “Patient Monitoring System” example in Section 4, you may find out the answers to these questions:
– Which one is the best model for your business? Edge or cloud AI?
– Can you use both solutions together?
2. Cloud and Edge Computing Definition
2.1. What is Cloud Computing?
The “Cloud” is the set of servers that store and manage software, documents, and other data over the internet. Cloud infrastructure refers to the hardware, software, and networking resources that enable cloud computing.
Cloud is a way to access your applications, documents, and services over the internet. It allows you to store data remotely, access it from anywhere, and share resources with other users. Cloud computing enables delivering on-demand computing services to users and companies. They also do not have to manage physical servers or run software applications on their own machines.
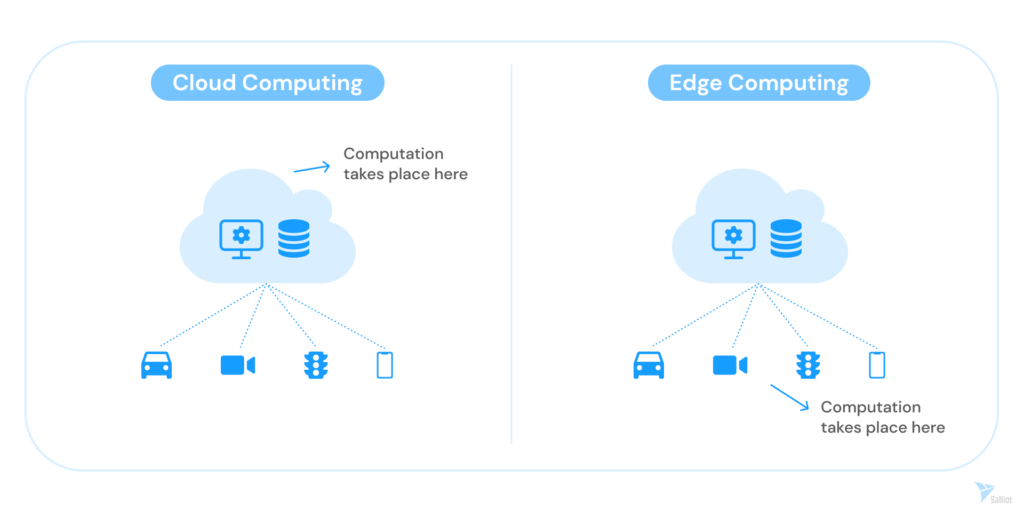
2.2. What is Edge Computing?
Edge computing is the philosophy of bringing our computational task as close to the source of data as possible instead of relying on the cloud to reduce latency and bandwidth use. In other words, edge computing means running fewer processes in the cloud and moving those processes to edge devices (local places), such as smartphones, IP cameras, smart vehicles, user computers, an IoT device, or an edge server.
Performing the computations on the network’s edge instead of the cloud reduces the amount of long-distance client and server communication. So, it decreases the latency, storage usage, and costs while increasing data privacy and speed.
You can visit this Galliot article to learn more about edge Computing, edge Deep Learning, and the advantages and applications of the edge in the industry.
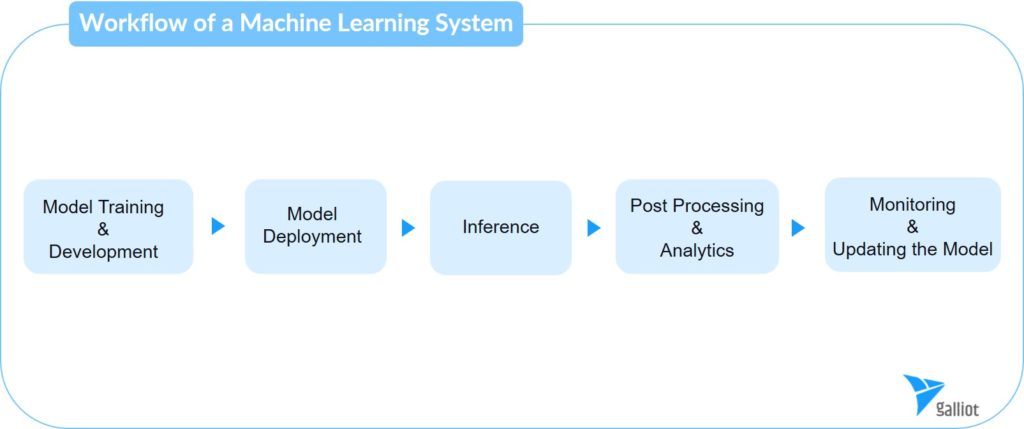
3. Workflow of a Machine Learning System
The workflow of a Machine Learning application can vary depending on the project’s type, scale, required AI tasks, etc. Based on these factors, you can build your AI application purely on the cloud, purely on edge, or use a combination of both technologies. In general, we can divide a Machine Learning pipeline into five steps: 1- Model Training and Development, 2- Model Deployment, 3- Inference, 4- Post Processing and Analytics, and 5- Monitoring and Retraining the Model.
3.1. Model Training
Model training and development is the process of creating a machine-learning model that can make accurate predictions or decisions based on data. This process involves selecting an appropriate algorithm, preparing the data, and training the model on the data.
Training a machine learning model can require a lot of computing power and take a long time, depending on the complexity of the model and the amount and quality of the data. It’s important to carefully plan for these computational needs when developing a model because they can affect how long and how much it will cost to train an effective model.
3.2. Model Deployment
It is the steps of making a trained machine-learning model available for use in production environments. This typically involves integrating the model into an application or system that can use the model’s predictions to perform a specific task. Model deployment requires careful consideration and monitoring of how the model will be used in practice and how it will be maintained and updated over time. During this phase, it is also important to consider issues such as model performance, scalability, and reliability. There are several options for deploying machine learning models, including cloud-based platforms, on-premise servers, and edge devices.
3.3. Model Inference
The inference phase is a machine learning project stage where the trained model gets used to make predictions or decisions on new, unseen data. The inference phase aims to use the model to accurately make predictions or decisions based on the learned relationships from the training phase.
3.4. Post Processing and Analytics
Usually, the output of the inference phase is not in a form that is understandable for users. So, passing this raw output directly to the user application does not provide any value for them. Instead, the output of the inference phase is typically processed and transformed into a more meaningful and understandable form. So it can be presented to the user through the application. This could involve formatting the output into a specific visual or textual format, performing additional calculations, or processing the output to extract relevant information or insights. This allows the user to understand and make use of the results of the inference phase.
3.5. Monitoring and Retraining the Model
Monitoring and retraining a model is an essential phase in the lifecycle of a machine learning system. It involves regularly evaluating the model’s performance in production and updating it with new training data if its performance degrades. This can be done by either updating the existing model or training a new one from scratch.
4. Hybrid Cloud-Edge ML Stack; Patient Monitoring Example
We will use a sample “AI-based Hospital Patient Monitoring” system to better explain a machine learning application workflow. In this example, we explore a system that combines the power of cloud computing with the low latency and high accessibility of edge computing to create a practical machine learning application.
In our “Hybrid Cloud-Edge ML Stack”, each step for building the application can take place either on the cloud or edge based on the capabilities and specifications of each infrastructure. In the following lines, we will elaborate on these considerations and talk about the architecture and workflow of this intelligent patient monitoring system.
4.1. AI-Based Patient Monitoring System: Problem Statement
Hospitals are constantly looking for ways to improve patient care and monitoring. One approach that has gained traction is using machine learning systems to analyze data from various sources to provide real-time insights and alerts to hospital staff.
Imagine you want to build a hospital patient monitoring system; Using the camera footage, the system can detect and record activities inside hospital rooms. The activities can be patients’ positions like being on/off the bed, their position in the room, when they are leaving the room, how many times nurses visit them, etc. The system also collects patients’ vital signs like heartbeat and blood pressure and integrates them with other data to produce better insights.
This system consists of three main components: 1- IP cameras and biological data sensors, 2- a core machine learning algorithm, and 3- a user platform (mobile / web app).
Both the camera footage and the biological data are transmitted to a machine learning model, which processes the data and sends relevant insights and alerts back to the mobile app. The mobile app can get used by hospital staff to monitor the patients and receive real-time alerts. It can also provide this information for companions (relatives) to know about their patient’s situation at any time from anywhere.

4.2. The Benefits of an AI-Based Patient Monitoring System
While this system can bring numerous benefits, here we mention some of the most important ones. The system can help hospital staff identify potential health issues early on by providing real-time alerts and insights. This allows timely intervention (like providing medication and care ASAP), which leads to improved patient outcomes. The system can also reduce hospital staff’s workload by automating some monitoring tasks. Moreover, providing a comprehensive view of the patient’s condition can help hospital staff make informed decisions about treatment options and improve overall patient care.
4.3. What are the Data Sources?
Before coming up with the system structure and formulating the solution, let’s talk about the foundation of every AI/Computer Vision model first; The Data. Our application’s main available data sources are as follows: The IP cameras installed in hospital rooms capture footage of patients 24/7. The biological data sensors, such as blood pressure monitors and heart rate monitors attached to the patients, continuously record their vital signs. The medical records of patients that show previous diseases and symptoms could be another data source in this system.
4.4. Formulating the Solution For AI Patient Monitoring App
The application uses a combination of computer vision and machine learning algorithms to process the data. Computer vision algorithms are employed to analyze the footage from the IP cameras and identify features such as the patient’s posture, facial expressions, and movements. The machine learning algorithms are then used to analyze the data from the biological data sensors and detect patterns and anomalies that may indicate potential health issues.
4.5. Combining Cloud Computing and Edge Computing in AI System
Assume that we have a pre-trained machine-learning model at the heart of our system. This model is trained on a large set of relevant data and is designed to identify patterns and anomalies that may indicate potential health issues. For example, the model is able to detect an increase in heart rate or a change in the patient’s posture that could indicate a potential risk or health problem. For such detection, we need to run a deep learning inference job on this model that can take place on the cloud or edge. But which one is the best option for this job?
While the cloud-based machine learning model is powerful and can handle heavy computations, it might not be optimum to transmit all data to the cloud for processing. For example, in the case of hospitals with limited or unreliable internet connectivity, it may not be possible to transmit large amounts of data to the cloud in real-time. This is while we can use edge computing to enable real-time data processing at the source. Moreover, we might have constraints in sending patients’ data, such as their footage, to external servers due to privacy-preserving issues.
Therefore, a better design would be employing distributed edge devices to get the raw data and run the deep learning inference on them. Then, the edge devices collect and transmit only the relevant insights and alerts to the cloud. It ensures data privacy and protection, reduces the amount of data needed to be transferred, and enables real-time processing. This way, we can solve the main problems with transmitting the raw data directly to the cloud servers.
💡 Read More: How can we handle the data transfers to Edge and Cloud?
The data can pass to the edge devices using a standard protocol like GRPC and RTSP, where the inference will happen. Then, we will send the structured data as JSON or ProtoBuf messages to a massage broker like KAFKA so it can push it to a cloud platform.
In the hospital patient monitoring application, we send the video streams from the surveillance cameras to the edge devices via RTSP protocol. Then our Deep Learning model detects the patients’ actions and identifies their position in the hospital room.
On the cloud side, we have services that can generate insights from inference data and biological sensors data. Later it sends the alerts and insights back to the client platform like a mobile application. The app receives insights and alerts from the cloud-based machine learning model and displays them to the user in an easy-to-understand form. This platform also allows the hospital staff to view the camera footage and biological data in real-time, providing them with a comprehensive view of the patient’s condition.
4.6. What are the Edge Devices in the Hospital Patient Monitoring System?
There are several types of edge devices ranging from small processing units like Nvidia Jetson family devices and Google Edge TPU to more powerful ones such as Lambdalabs edge AI GPU boxes. In the system we are designing, we can connect the available devices, such as IP cameras and biological data sensors, to our edge processors. These devices will be equipped with onboard processing capabilities and are capable of running machine learning models locally.
4.7. Model Degradation and Continuous Learning
“The measure of intelligence is the ability to change.”
– Albert Einstein
Various reasons might degrade the performance and accuracy of a deep learning model in time, known as Concept / Data Drift. It means the changes that happen to the data or the statistical properties of the model’s target variables over time in an unseen way. In our hospital monitoring system, each room has a different type of bed, camera angle, lighting, background, etc. All of these properties can change over time. So, we need a system, such as continuous learning, to continuously monitor, train, and deploy new models through time.
As we know, due to resource and computation limitations, most edge devices are not suitable for such training. So cloud computing is preferred for training at this level. There are lots of cloud services and platforms like Amazon SageMaker designed for fast and high-performance model training. We can set up some pipelines on the cloud side to create training data with the help of human operators or labeling tools for labeling them. This data is then automatically fed to training services to train the models, manage artifacts, etc. Finally, the trained models need to go to another service responsible for deploying the models on related devices.
5. Conclusion
Cloud and edge computing have significantly improved how we build and run machine learning applications. However, each has strengths and weaknesses in different situations. While the cloud is powerful for training heavy models, low latency and high accessibility of edge computing enable real-time processing.
In this article, we used an instance use case to explain the hybrid cloud-edge ML stack for building an AI system. We discussed a system that combines the power of cloud computing with the low latency and high accessibility of edge computing to enable effective patient monitoring in hospitals.
Do you need further consultancy to find out which solution is best for your project or business? Get in touch with us using the contact form or via hello@galliot.us.
Get Started
Have a question? Send us a message and we will respond as soon as possible.
Leave us a comment