Edge Deep Learning

image source by coral.ai
Here we introduce deep learning, provide examples of edge deep learning in the industry, explain the benefits of deploying edge deep learning to your product, and introduce different hardware architectures as well as available development kits.
This is the first part of Galliot’s articles on edge deep learning. Deep learning and edge computing are discussed in this part at a high level. The upcoming parts of this article will cover the technical detail you need to work with edge deep learning technologies.
Visit our Edge Deep Learning projects from this GitHub repository.
To build a unique deep learning model, you will require massive data labeling. You can read more about data labeling approaches and methodology in this blog post.
1. What is Deep Learning?
Deep learning is a subset of Artificial Intelligence (AI) techniques. It is currently the most robust and accurate method for solving AI problems. It solves problems that used to be too complex for traditional AI engineers to beat human-level accuracy. These problems include playing and winning complex strategic games like Go, computer vision tasks like detecting objects in images and videos, classifying the type of an object -like an animal- in an image, summarizing texts, translating speech in real-time, and generating fake videos which are almost indistinguishable from original without the help of deep learning itself.

Deep Neural Networks (DNNs) are the fundamental structure at the core of all deep learning applications. DNNs have multiple consequent layers of calculation units, with the capability of learning the common patterns of concepts among a vast amount of input data. These concepts can be low-level patterns like corners, edges, lines, and circles, or they can be high-level patterns like a human face or an object like a chair.
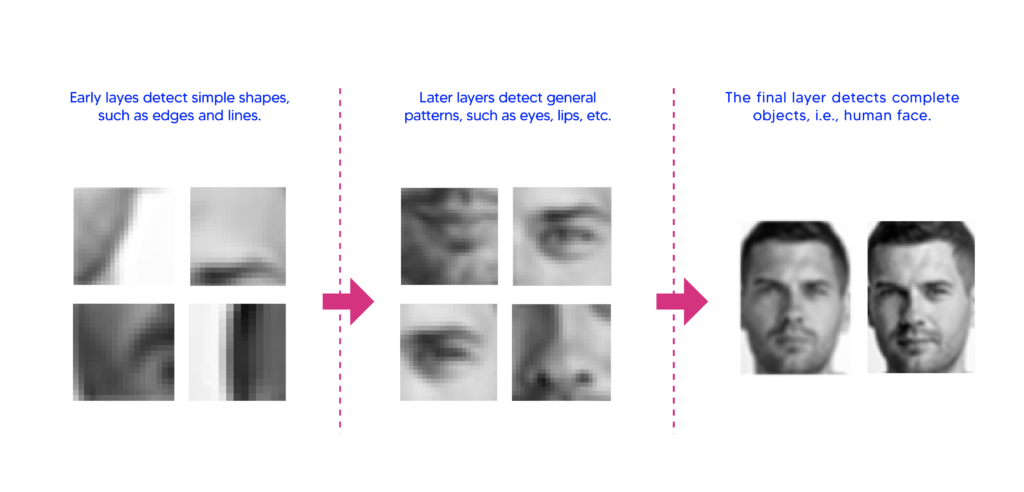
In the sequence of layers in a DNN, initial layers are specialized for learning low-level concepts, and final layers are specialized for learning high-level concepts. Each layer builds upon its preceding layers’ understanding to represent higher-level and more abstract concepts. Figure (2) shows how DNNs perform face detection, first by learning lines and edges and then finding more complex patterns in a face. DNNs can also find complex patterns in other types of data, like voice, text, and time series.
1.1. Deep Learning Problem Structure
Deep learning programs are expected to generate the correct output for the input provided to them. In most deep learning applications, both input and output are simply represented as a sequence of numbers.
In order to train a model and evaluate the performance of a deep learning program, we need a Dataset of sample <input, expected output> pairs. There are many publicly available datasets for various deep-learning applications. For example, Google has published 81 datasets for various applications, including the Open Images with ~9M images and the AudioSet with ~2M audio samples. Figure (3) shows a popular handwritten digit classification dataset called MNIST, containing 70,000 examples.

In the handwritten digit classification task, the input is an image taken from a handwritten digit. Our goal is to find out which digit the input image represents. It might seem obvious for our brain to recognize the output digit. However, as shown in Figure (4), it is challenging to come up with an algorithm that recognizes the digit out of a sequence of pixels’ brightness levels.

1.2. Deep Neural Networks (DNNs)
This section provides an intuitive explanation of how DNNs work in handwritten digit classification. The content is highly inspired by the wonderful 3blue1brown’s “Deep learning, chapter 1” video.
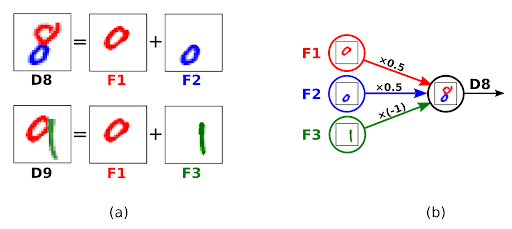
The building blocks for DNNs are pattern detector units called neurons. Complex patterns can be represented by a combination of simpler sub-patterns. For example, figure (5-a) shows how the pattern for two digits (D8, D9) can be defined as a combination of three simpler sub-patterns (F1, F2, F3).
Each neuron is specialized in detecting one pattern in the input image. Every time an input image is provided to the DNN, each neuron looks for its pattern in the image and calculates a score called activation. Neurons that find their corresponding pattern present in the input image produce a score of 1 or more. Neurons that don’t detect their pattern produce an activation of 0.
In order to find out whether the pattern is present in the image, each neuron checks the scores produced by neurons of simpler sub-patterns. Then, as shown in Figure (5-b), the score of each sub-pattern is multiplied by a weight number. Finally, the neuron sums up the weighted sub-scores to calculate its own score. For example, neuron D8 calculates its activation score using the score of 3 simpler neurons F1 (a circle on the top), F2 (a circle at the bottom), and F3 (a vertical line on the right). The connections from F1 and F2 have a positive weight of 0.5 because their patterns (circles on the top and at the bottom) are sub-patterns of D8. However, the connection from F3 (a vertical line) has a negative weight of -1 because a vertical line is not a sub-pattern of digit 8.
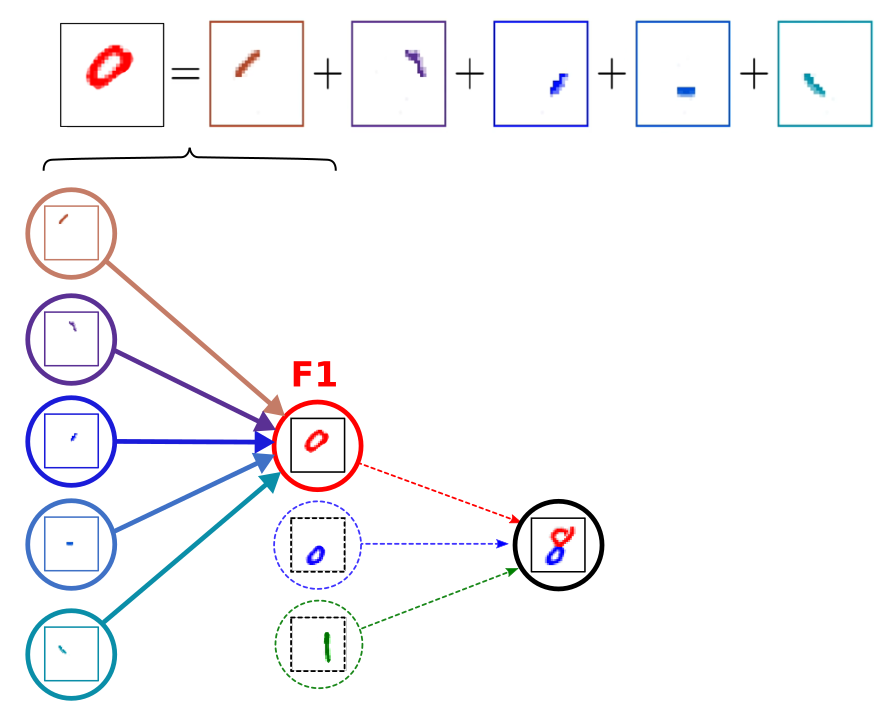
This decomposition of patterns into smaller sub-patterns can be extended to F1, F2, F3 themselves too. Figure (6) demonstrates how the neuron for calculating the score of a circle pattern uses the activation scores of simpler angular edge patterns.
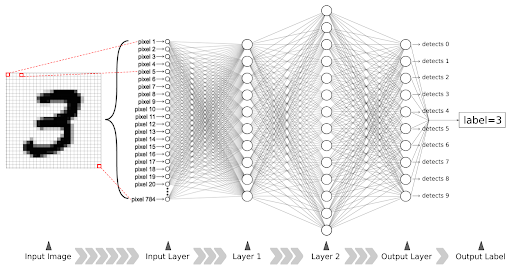
Finally, the simplest pattern in an image is the brightness of a single pixel. As shown in Figure (7), each pixel has a corresponding neuron in the first layer of a DNN, called the Input Layer. The neurons in the input layer do not have incoming connections. Their activation score is the brightness of their corresponding pixel. The neurons of Layer 1 detect small angular edges and corners using the input layer activations. The neurons of Layer 2 detect shapes like lines and edges. Finally, the output layer contains 10 neurons. Each neuron calculates the score for one digit in 0 to 9. The output label is determined by finding the neuron with the highest activation score.
1.3. Deep Learning Training
In the previous section, we demonstrated how a DNN could understand a handwritten digit by looking for simple patterns first and combining them incrementally until the actual digit is detected. However, the success of a DNN depends on the correct definition of patterns for each neuron. Otherwise, the DNN would look for irrelevant patterns as evidence and would eventually fail to find the correct output. Now, the question is how to define these patterns and abstractions?
As a huge DNN has hundreds of thousands of neurons and hundreds of millions of connections between the neurons, it is not practical to define the patterns manually. One of the greatest strengths of deep learning is the ability to learn these patterns from data automatically, as it is called the training process, using an optimization technique called back-propagation.
The important property of DNNs is that the whole set of patterns looked up by neurons of a DNN is defined by the weights of connections between the neurons. The computations for calculating the activation score of neurons with respect to these weights are defined in such a way that optimization techniques can modify the weights to find better patterns looked up by neurons, improving the accuracy of the DNN.
The optimization process starts with a random DNN that detects random noise patterns. In the handwritten digit classification task, the initial random network has only 10% accuracy. However, the optimization algorithm iteratively takes <input, output> pairs from the dataset and slightly refines the connection weights between neurons so that the score of the correct neuron in the output layer increases and the score of the rest of the neurons in the output layer decreases. Each iteration slightly improves the patterns of neurons. By running enough iterations, DNNs tend to converge to an optimal set of values for the connection weights and patterns for neurons. According to the State-of-the-Art benchmark, an accuracy of 99.84% is achievable on the MNIST dataset for handwritten digit classification.
1.4. Deep Learning Inference
The training process converts a random DNN to a high-accuracy DNN. This process requires multiple passes of running the optimization algorithm over the whole training dataset. Finding the accurate set of connection weights and patterns for a DNN is extremely computationally expensive. For example, training Google’s BERT model requires 2 weeks of computation on a Cloud TPU. [1]
Once the training is done, the connection weights of the optimized DNN are saved to a file so that the weights can be loaded again in a few seconds or minutes. Once the optimized weights are loaded, the DNN is accurate and functional. The inference is the process of using pre-trained weights for using the DNN with new inputs.
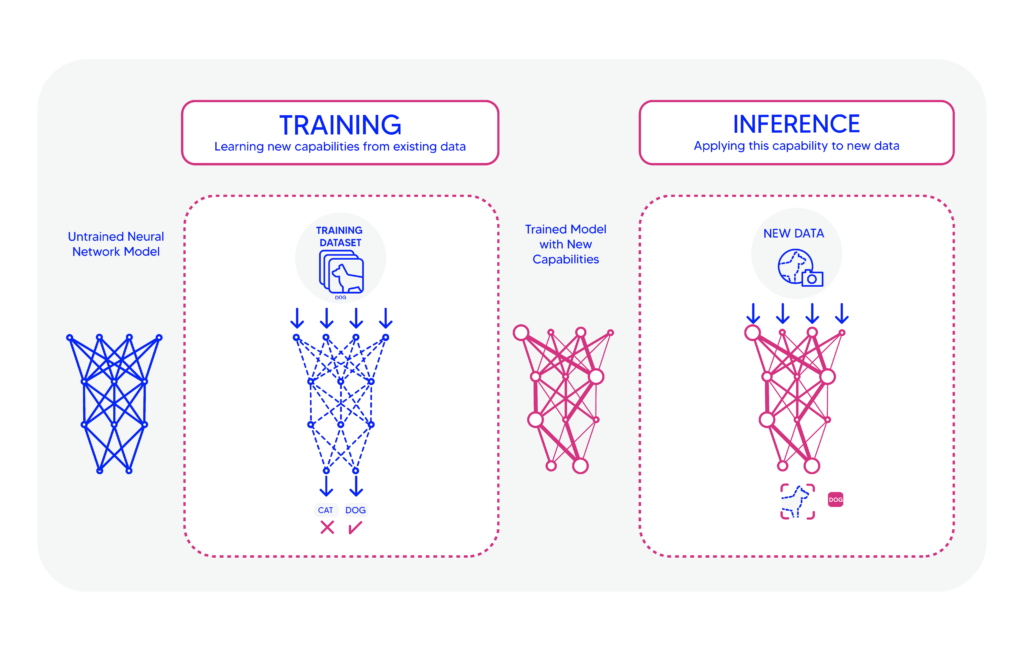
In comparison to the training, the inference requires significantly lower computations. While clusters of high-power computation devices (GPUs, TPUs, ..) are required for the training process, the inference can be run on low-power edge devices.
2. Inference on the Edge; The Essense
Deep learning algorithms are known for high resource consumption. In the training phase, millions of parameters are iteratively refined to fit the data. In the inference phase, millions of computations need to be performed on the input data (with potentially high dimensions). In fact, deep learning computational complexity and hardware limitations were some of the most important reasons why deep learning didn’t become very popular in its early ages back in the 1980s.
2.1. Cloud Computing and Deep Learning
With the advancements in computer hardware and cloud computing, deep learning has become more popular than ever. Following a paper that introduced GPUs to large neural networks in 2009, record-breaking achievements started to happen in deep learning. Cloud computing has made deep learning models fast and accessible, and some companies are storing and processing their data in the cloud.
With cloud computing, however, a massive amount of the data needs to travel from the data source location to a central data center, often thousands of miles away, for deep learning inference and then back to the device of origin. This often long distance between the data source location and the data center, together with the expensive network and bandwidth requirements, has forced some limitations to the cloud-based solutions. Some of these limitations include latency, lack of scalability, security and privacy concerns, and high bandwidth costs.
2.2. Edge Computing
In some cases, applications need real-time inference; otherwise, they will not be usable. In such cases, cloud computing is not the solution. Edge computing, however, meets the latency, scalability, privacy, and bandwidth challenges mentioned earlier. In edge computing, processing takes place close to the end devices, at or near the “edge” of a network. Edge computing circumvents the need to access the cloud to make decisions and allows deep learning applications to run in near real-time or real-time.
Inference on edge is a viable solution for your application if you prefer speed over accuracy, you want to spend less money on network infrastructure, and you need to cut power expenses. We will explain some of the advantages in the next section.
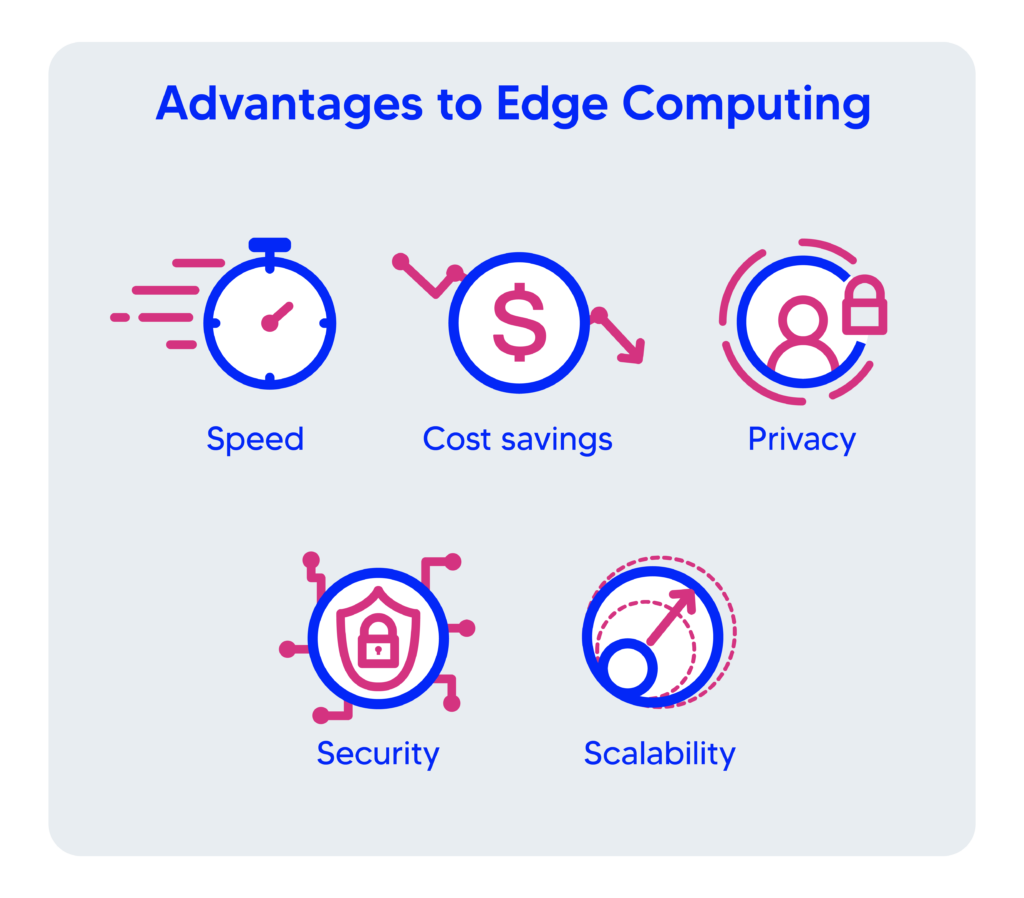
3. Advantages of Edge Computing
Many companies are now using edge computing for different purposes, from object detection and image classification applications to IoT management. Some of the advantages of edge computing are as follows:
- Speed. In many applications, such as self-driving cars, milliseconds are a matter of life and death, and cloud computing is not a practical solution. However, by performing computations at the edge, edge computing eliminates latency and makes real-time deep learning inference happen.
- Privacy. Edge computing addresses data privacy by processing a portion of the data locally at the edge, in comparison to cloud computing, which sends all the data over the internet. For example, smartphones are now processing some of the user’s personal data, such as biometric identifiers, at the edge rather than sending it to the cloud to preserve the user’s privacy.
- Security. Since traditional cloud computing architecture is essentially centralized, it is highly vulnerable to security threats such as DDoS attacks. By distributing data analysis tools across a wide range of devices and data centers using edge computing, security risks are distributed as well.
- Cost Savings. Edge computing optimizes the data flow that needs to be transferred to the cloud. By performing most of the calculations at the edge, companies can save money on bandwidth costs. Also, power-efficient edge devices can reduce energy costs for businesses. For example, Google’s Edge TPU can perform 4 trillion operations per second using only 2 watts of power.
- Scalability. Cloud computing requires a massive infrastructure for support, and if a company wants to expand, it has to spend some money on additional cloud infrastructure. This extra cost makes the service more expensive for clients. However, edge computing is scalable because the data is stored with the user. Therefore, companies that are using edge devices don’t need to worry about the extra costs if they want to expand.
4. Edge Computing Applications in Industry
Edge computing applications in the industry are numerous. In this section, we explain two well-known applications of edge computing in detail to elucidate the functionality and practical benefits of edge computing in the industry. Other applications of edge computing have already been developed in different areas of healthcare, agriculture, entertainment, transportation, advertising, commercial cleaning, and more.
4.1. Smart Home
The smart home is one of the emerging applications of IoT that plays a crucial role in popularizing edge devices. Zion Market Research predicts an annual growth rate of 14.5% in the global smart home market since 2017, reaching approximately USD 53.45 billion by 2022. There are several applications of edge computing in smart homes:
– Preserving home security. On-the-edge services such as Constellation Connect are designed for smart homes to detect suspicious activities such as housebreaking attempts. While home security is being preserved, sensitive home data is also being protected as most of the computations take place locally on edge devices.
– Ensuring the safety of children and the elderly. Edge computing can be applied to smart homes to keep children and the elderly safe. For example, fall detection systems can be implemented in a smart home to detect the elderly’s falling. They can produce medical alerts automatically, allowing the elderly to summon help without having to reach out to their phones.
– Detecting threatening events. Edge devices can quickly detect hazardous events, such as gas leaks or fires, to avoid potential damage. For example, in case of a gas leak, edge devices can detect the threat in real-time and shut down the gas supply of that home immediately without suffering from cloud computing latency issues.
– Utilizing energy management plans. Edge-based energy management systems, such as smart heating systems, can increase energy efficiency and decrease energy use expenses. Sensors, actuators, and smart devices interact at the edge to reduce data transfer to the cloud and minimize computing and network bandwidth costs.
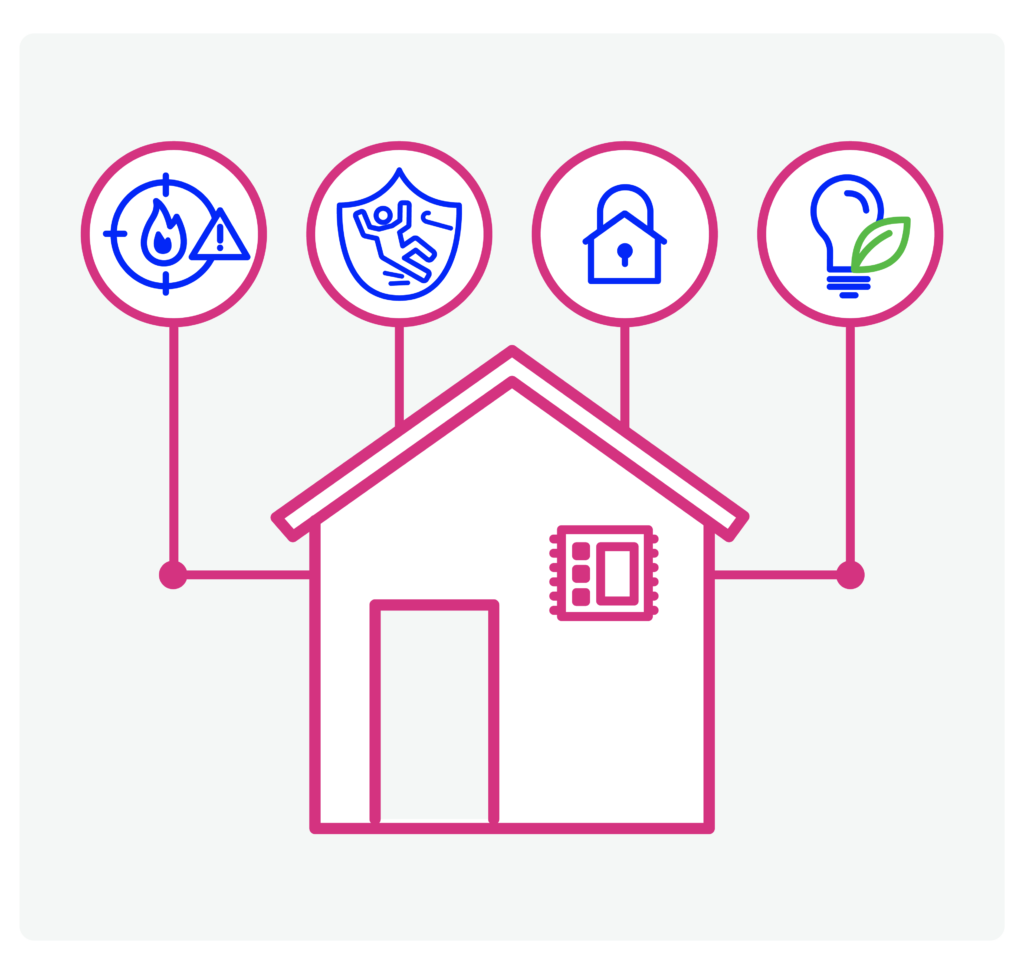
Figure 10. Edge deep learning applications in smart homes.
4.2. Manufacturing and Industrial Robotics
Industrial machinery produces large amounts of data that can be further analyzed to give manufacturers insights about different equipment in factories. Data can be analyzed locally with the help of edge computing in near real-time or real-time to detect anomalies in devices and perform predictive analytics to identify component failures. By eliminating the need to transfer data to a cloud system, edge computing minimizes storage and bandwidth rates as well as latency costs.
Edge devices can measure key machine parameters such as rounds per minute, energy consumption, and device temperature to identify areas for improvement and increase efficiency. Environmental controls such as lighting and cooling can also be monitored using edge devices to reduce energy costs in factories.
Manufacturing at the edge is interoperable, which means it can provide the necessary protocol translation for communications to be established between devices that are not able to communicate using IP/Ethernet interfaces. Interoperability can provide IoT solutions to both legacy and modern machineries and helps manufacturers capture insights about different equipment.
Edge computing also transforms industrial robotics. With the advent of technology in driverless technologies and edge computing, warehouse automation has become more popular among businesses. Autonomous forklift robots can manage warehouse operations and eliminate warehouse catastrophes with the help of embedded edge devices.
Robots also generate massive amounts of data that can help manufacturers increase efficiency if handled correctly. For example, Fanuc’s Gakushu Robot uses computer vision and machine learning software to collect and evaluate data for path, speed, and task optimization in aerospace manufacturing. The Gakushu Robot with Learning Vibration Control (LVC) provides swift cycle times, which optimizes production throughput.

5. Embedding Deep Learning Into Your Product
Using the edge device that best suits your specific needs, you can deploy deep learning to your product. In this section, we look at the hardware landscape as well as different edge architectures and available edge development kits in more detail.
5.1. Hardware Landscape
Many companies started investing in developing edge development kits and deep learning accelerators as deep learning and artificial intelligence technologies began to change the world in the 2010s, from Google, Microsoft, and Apple tech giants to IC vendors such as Intel and NVIDIA, to early startups such as Habana.

The number of companies that are deploying edge deep learning technologies is increasing, as well as the variety of products. Today, there are plenty of edge development kits to choose from that can perform almost every deep learning task at the edge. We discuss some of the edge development kits available in the next section to give you a better insight into current market solutions for edge deep learning.
5.2. Edge Architecture
Each edge product has unique characteristics that make it suitable for specific use. For instance, in terms of power, the different edge products can be grouped into three categories, from the low-power NDP101 devices used for keyword classification in speech recognition applications to the high-performance autonomous car-specific systems from NVIDIA, Mobileye, and Texas Instruments.
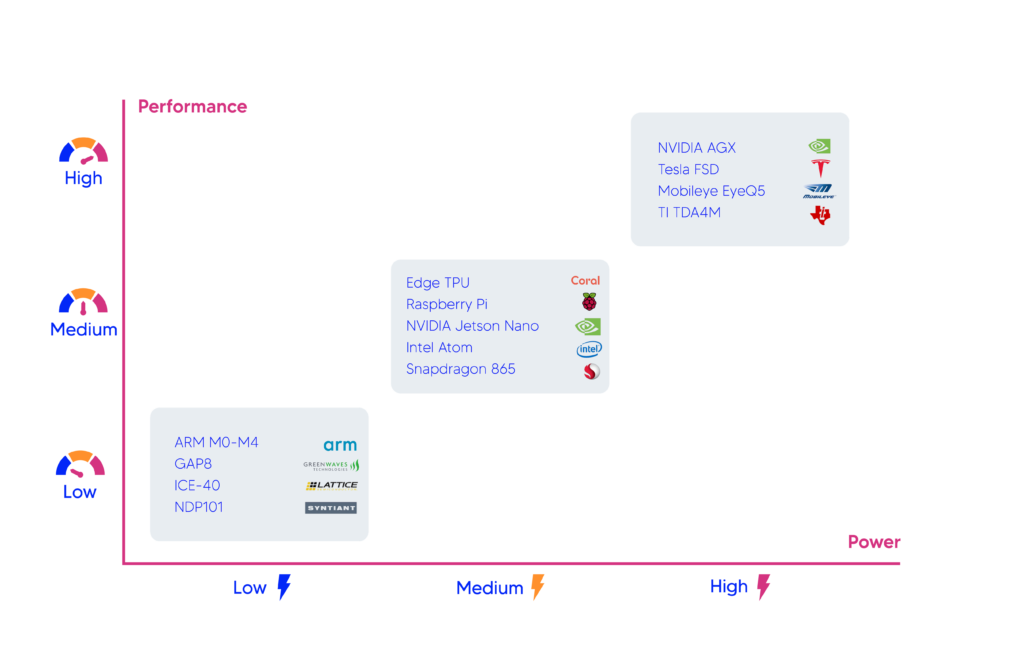
There is a trade-off between power usage and inference accuracy/speed; therefore, you need to prioritize one over the other. Medium-power devices such as Edge TPU and NVIDIA Jetson Nano run deep learning applications in near real-time, and they don’t consume a significant amount of power. Thus, they are generally a good choice for deep learning applications.
Each edge product is made up of 4 layers: 1- the hardware layer, 2- the OS layer, 3- the machine learning runtime layer, and 4- the edge application layer.
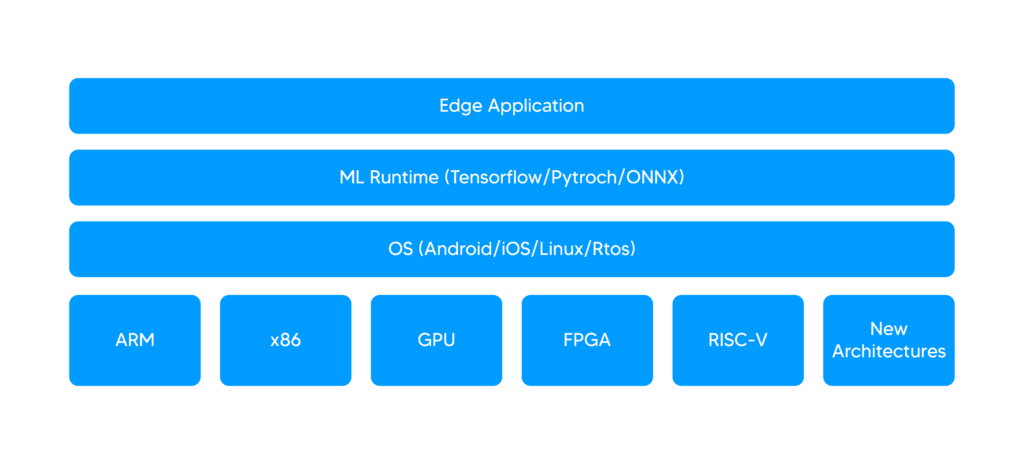
- The hardware layer specifies the processor architecture. Common architectures include x86, used in the majority of personal computers, and ARM architecture which is extensively used in consumer electronic devices such as smartphones.
- The OS layer includes the software and settings for the operating system. Android, iOS, and Linux are some examples of different operating systems that are designed for various devices, such as smartphones and personal computers.
- The ML runtime layer includes different frameworks, such as TensorFlow, PyTorch, and ONNX. Tensorflow allows developers to create large-scale neural networks with many layers, PyTorch is a Python-based machine learning library that is mostly used for computer vision and natural language processing, and ONNX is an open format built to represent machine learning models.
- The edge application layer is built on top of the other layers. This layer manages the user interface components and delivers the final product.
5.3. Edge Development Kits – Edge Devices
We now introduce some of the most popular edge development kits that are currently available to developers for developing edge artificial intelligence applications:
1- Google Edge TPU
As part of the Coral platform, Google Edge TPU devices are presently available in two forms of Google Coral Dev Board and Google Coral USB Accelerator, both programmable using TensorFlow Lite.
2- NVIDIA Jetson Nano Dev Board
It is a small, powerful, low-cost AI computer that is supported by NVIDIA JetPack and can run multiple neural networks in parallel without consuming much power. The dev board is available from $99.
3- Intel Neural Compute Stick 2 (Intel NCS2)
As small as a USB flash drive, Intel NCS2 has brought fast inference to the edge. The Intel NCS2 is programmable in the Intel Distribution of OpenVINO toolkit and can be developed on Windows, macOS, or Ubuntu. This device is available for $99. Other edge development kits include Sparkfun Edge Development Board, Sipeed M1 dock suit, and AWS DeepLens.

5.4. Edge Deep Learning Deployment Challenges
Several challenges remain in deploying deep learning on edge, from choosing the right hardware that best fits our needs to technical implementation difficulties. Some important challenges are as follows.
– Memory limitations. Usually, neural networks are large in terms of size, and edge devices don’t have enough memory to handle large networks. You can only run highly optimized models on edge devices to get accurate performance results.
– Additional technical considerations. Building your own model requires some technical considerations aside from being highly optimized. For example, to use Google Edge TPU, one of the requirements is that your model parameters should be constant at compile-time. You can read about other Google Edge TPU model requirements here.
– Less model accuracy. Most neural network parameters are 32-bit float values, but edge devices tend to handle 8-bit values. This limitation results in faster but less accurate inference.
– Complicated installation process. Although there are many great step-by-step tutorials available to help you with edge deep learning, getting started is still a long process that requires patience and can be quite complicated. You may need to install some dependencies on your system and read about a few things before you can get started.
There are some other challenges, as well. However, the pace of innovation in edge deep learning remains high. With getting a little help from AI engineers, companies gain substantial benefits by deploying deep learning on the edge.
This is the first part of Galliot’s four-part long article on edge deep learning. Deep learning and edge computing are discussed in this part at a high level. We provide examples of edge deep learning in the industry, explain the benefits of deploying edge deep learning to your product, and introduce different hardware architectures as well as available development kits.
The upcoming parts of this article will cover the technical detail you need to work with edge deep learning technologies.
Visit our Edge Deep Learning projects from this GitHub repository.
Get Started
Have a question? Send us a message and we will respond as soon as possible.
Leave us a comment