Is Machine Learning Right Solution For Your Project?

What is the "right tool" to solve your problem? - image by: galliot.us
Along with the extensive AI/ML use cases, it has various challenges to address first. Here is a framework for companies to know if Machine Learning approaches can help their business.
Are you new to Machine Learning and Deep Learning?
Explore our blog page or visit our solutions page for more examples of AI in practice.
Find out how to deal with data labeling requirements for building better AI applications.
Inspired by the book: “Designing Machine Learning Systems“
― by Chip Huyen
1. Introduction
In recent years, there has been a huge amount of excitement and hype around Machine Learning and Artificial Intelligence. People inside and outside the field thought they could solve any problem with these tools. However, ML is not a magic tool to solve all problems. Even for the problems that ML can solve, there might be many challenges. Therefore, in many cases, these misplaced expectations cause financial and time losses for companies.
This article presents a framework that can help companies determine if a machine learning or artificial intelligence approach is suitable for solving a particular problem or project. By using this framework, companies can make informed decisions about whether these technologies can benefit them or not.
Imagine you are a manager in a healthcare company that produces drugs or medical equipment and offers maintenance services. So how can you decide whether ML can solve your specific problems in your business or not? We try to approach this question in this blog post.
2. There Must Be Something to Learn
As its name suggests, a Machine Learning system can learn patterns and relationships. In most cases, ML systems learn these patterns from data. For instance, supervised learning needs labeled data that forms input/output pairs. So the model can learn some of the relations and patterns between these input/output pairs. After training, it can predict the output when an arbitrary input comes to the system.
Imagine you want to build an ML system based on CT scan images to learn to predict whether a detected mass is Benign or Malignant. First, you must prepare a dataset of CT images and a label that indicates the kind of mass for each particular image. Once learned, this ML system should be able to predict the type of masses given the CT images.
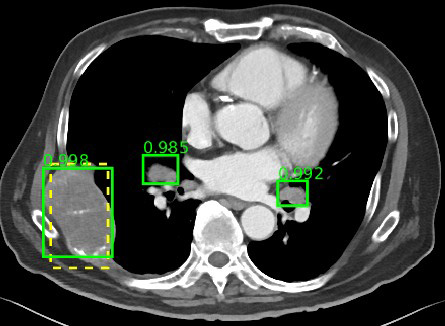
3. There Must be Patterns in the Data
ML systems only work when there are patterns in data. For instance, no machine learning model can predict the color of the next passing car from a crossroad. This is a random event, and there is no pattern of how the outcome of this event is generated. However, there are patterns in how a person has diabetes. So you can create an ML model to predict the risk of getting diabetes based on various factors.
Note that patterns can exist, but sometimes they can be so complex that it may seem like there is no pattern. In this case, the only solution is to train different machine learning models, from simple to complex ones, to see if they can perform well and train something.
4. Patterns Must be Complex
No one uses a machine learning system to sort a hospital’s patients based on age. Although this data has a pattern, it is too straightforward, and you can use a simple lookup table. On the other hand, suppose you want to sort the patients based on the probability of their need for further care. Here you will find the relationship of this event with other patient factors much more complex than the age sorting problem. Thus, using an ML system will be a logical choice.
5. Data Availability
Since ML systems learn from data, there must be data for training a machine learning model. Therefore, before choosing machine learning to solve a problem, you must check whether you have enough data with acceptable quality or not. If appropriate data is unavailable, you may incur significant costs to collect and label the data, depending on the scope of the problem.
There are several ways to gather and label required datasets, such as crowdsourcing and in-house labeling. You can read this comprehensive article on data labeling best practices and methodologies to get familiar with its process.
You may find that there is little or no data available before launching a machine learning system. Still, you can generate useful data immediately after launching the system through the interaction of users with the system. You can use the Continual Learning method for this work. This way, you can start with a system that has been trained with a small amount of data or even a non-machine learning approach. Over time and with the accumulation of data, we continuously train the system in specific periods.
For example, we might not have enough data about our users and their preferences to train a Recommendation System. So, we launch a system that suggests popular products to everyone. Later, we can begin training a recommender system using the generated data from our users’ interactions with the system. As time passes, users generate more data, and as a result, the recommender system gets better.
6. Distribution of Unseen Data
What is the goal of training a machine learning model?
We usually train an ML model to estimate/predict a value not seen by the model in the training phase. So the trained model is only practical when the unseen data has the same pattern as the available data in the model training phase.
For example, if you want an ML system to predict the effectiveness of a new medication for adults, you should not train it with other age groups, such as children.

7. Repetitive Patterns
In contrast with the human brain, most machine learning algorithms need lots of data to work properly. With a large amount of data, most of the patterns will be repeated multiple times, making it easier for the model to learn them. Some ML approaches can work with sparse patterns in data, such as Few-Shot / Zero-Shot Learning. So if you have a problem in which the dataset size and patterns’ repetitiveness are small, you should either not use ML at all or consider using few-shot learning methods.
8. Cost of the Wrong Prediction
No Machine Learning model is perfect and will surely have some mistakes. So if the wrong prediction cost is high for your problem, you should be careful about employing Machine Learning.
For example, consider a video captioning application; the video streams to a machine learning system to describe the scene and predict the speeches in text format. As we said, this system may have errors in some situations. However, this error can be forgivable since it does not affect someone’s life. In contrast, for a cancer detection system, if the model predicts that a patient does not have cancer while he actually has, it can put someone’s life in danger.
Another good example is AI’s application in “Self-Driving Cars”; these cars use various machine learning algorithms such as object detection and semantic segmentation to see the surroundings, extract information, interpret the data, make decisions, and take action.
Here we can consider two different categories of AI use cases. The first is assistive applications such as Emergency Braking, Driver Sleep Detection & Alarming Systems, Lane control, etc. As you guess, even with a wrong prediction in these tasks, there will be no harm to the driver.
The second one is the autonomous decision-making of AI in these cars. Here the driver leaves almost everything to the vehicle (ML model). A wrong decision or error in detecting objects or signs might lead to an accident and put someone’s life in danger.
Notice that machine learning algorithms can continuously learn these tasks and eventually perform them even better than humans.
Altogether, even when a prediction mistake can have catastrophic consequences, ML is still a suitable solution if: On average, the benefits of correct predictions outweigh the cost of wrong predictions. Moreover, we can put a human operator in the middle of the system to verify the output of the ML model. In this case, the ML does not do all the job, but it assists a technician or an operator in doing it faster and more accurately.
There are various measures helping users to learn more about the model’s limitations and the condition in which it performs the best. These actions increase the users’ awareness and enable Trustworthy and Responsible AI. Google Model Cards are an example of these efforts that increases transparency by providing key information about the machine learning model.
9. Scale of the Project
Creating an ML system requires lots of investment in talent acquisition, infrastructure, and data gathering and labeling. If the system is supposed only to run a few times, it may not be worth investing in creating it. But if it is going to run like a million times a day and yield a considerable saving of funds in the future, you can think about this investment. Having a problem at a large scale also means a lot of data for you to collect, which is helpful for training ML models.
10. Do Patterns Change Constantly?
“Everything is going to change. We just need to see how those changes are going to play out, for better or worse.”
― Emory R. Frie, Enchanted Forest
Living in the modern world with the prevalence of the internet and digitalization makes all of us hasty. Trends change every month dragging our taste with themselves. So, what’s the hype today may get old news tomorrow. These all mean constant changing of patterns in today’s world.
It is possible to use a series of handwritten rules or hardcoded solutions for problems with fixed patterns. But using these rules becomes practically impossible and expensive when the patterns change regularly. Here, the power of machine learning algorithms reveals itself. Since ML learns from data, you can update your machine learning model with new data without even knowing how the data has been changed.
For instance, in the Continual Learning approach, you can constantly train your model with new data, so the model continuously learns the latest patterns and will be updated.
11. Conclusion
Artificial Intelligence and Machine Learning techniques are extraordinary tools to improve various aspects of our businesses, lives, health, etc. But, they are not supposed to be beneficent and functional in all our problems. We can not expect ML to have profitable results in every project we implement. So, before deploying machine learning in a project, we must evaluate the pros and cons of using AI/ML systems in our specified problem.
Here we tried to provide a framework that can help companies evaluate the use of ML in their project and decide whether to use it or not.
If you need a consultation about AI & ML implementation, contact Galliot’s team of experts through the contact section or via email at hello@galliot.us.
Leave us a comment
Comments
Get Started
Have a question? Send us a message and we will respond as soon as possible.
I like what you guys are up also. Such clever work and reporting! Keep up the excellent works guys I have incorporated you guys to my blogroll. I think it will improve the value of my site 🙂
Aw, this became an exceptionally nice post. In idea I have to set up writing like this additionally – taking time and actual effort to make a good article… but so what can I say… I procrastinate alot and also by no means manage to go accomplished.