Real-world Face Mask Detection Part1; Problem Statement

image source freepik.com
In this article, we cover the mask detection problem, details about our synthetic ddataset, and classifier that can identify if people are wearing a face mask or not in real-world scenarios.
This is the first part of a two-part series on real-world face mask detection by Galliot.
Skip to the second part to see how we built a Face Detector working on real-world data.
Visit our Solutions Page to see other solutions by Galliot.
Read our Guide to Data Labeling article to learn about different approaches for handling labeling needs.
Wearing a mask in public settings is an effective way to keep the communities safe. As a response to the COVID-19 pandemic, we open-sourced a face mask detection application created by Galliot that uses AI to detect if people are wearing masks or not. We focused on making our face mask detector ready for real-world applications, such as CCTV cameras, where faces are small, blurry, and far from the camera.
This series has two parts; In this post, we present a series of experiments we conducted and discuss the challenges we faced along the way. We also cover the details about our mask/no-mask classifier. In part 2, we will go over building a face detector that can also detect small faces in real-world data. We will also deploy our face mask detector on edge and explain some code base configurations.
We have published our dataset (click to download) and our trained face mask detector model to share the results with the community.
1. Mask Detection Problem statement
Before getting started, let us understand the problem better. We want to build a system that can detect faces in real-world videos and identify if the detected faces are wearing masks or not. So, what do we mean by real-world videos?
If you look at the people in videos captured by CCTV cameras, you can see that the faces are small, blurry, and low resolution. People are not looking straight at the camera, and the face angles vary from time to time. These real-world videos are entirely different from the videos captured by webcams or selfie cameras, making the face mask detection problem much more difficult in practice.
In this blog post, we will first explore mask/ no mask classification in webcam videos and next, shift to the mask/ no mask classification problem in real-world videos as our final goal. Our reported model can detect faces and classify masked faces from unmasked ones in webcam videos as well as real-world videos where the faces are small and blurry and people are wearing masks in different shapes and colors. We will explain more details about the face detector in the next part.
2. The inspiration
Several online sources for face mask detection are currently available on the internet, such as this post by Adrian Rosebrock from PyImageSearch. These systems can detect face masks in videos where people are placed in front of the camera. Here is a demo video by PyImageSearch that shows how this system works in practice:
Since no dataset annotated for face mask detection is currently available, a model cannot be trained to detect faces and do a mask/ no mask classification simultaneously. Thus, most current solutions divide the face mask detection system into two sub-modules; 1- the face detector and 2- the mask / no-mask classifier. The detector detects faces in the video stream, regardless of wearing a mask or not, and then outputs bounding boxes that identify the faces’ coordinates. Next, the detected faces are cropped and passed to the classifier. Finally, the classifier decides if the cropped face is wearing a mask or not.
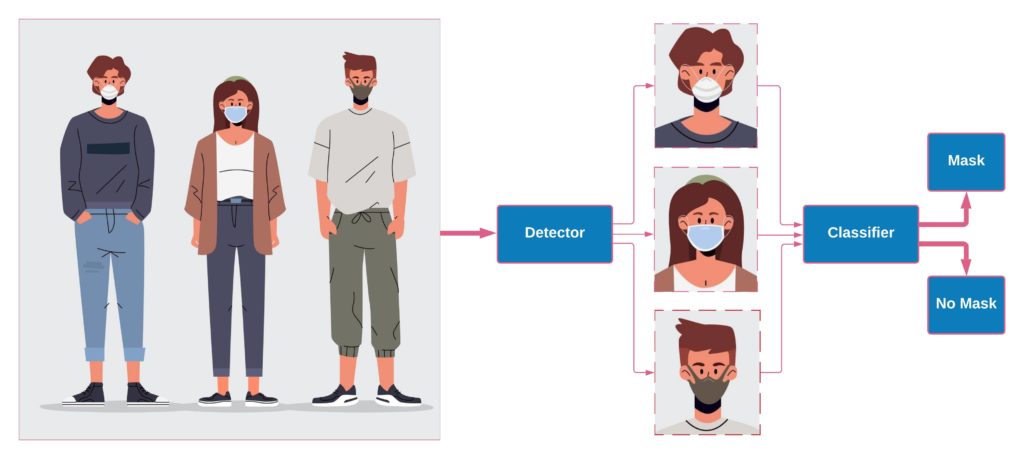
For example, in the mentioned post by PyImageSearch, a Single Shot MultiBox Detector (SSD) pre-trained on the WIDER FACE dataset is used for face detection. Also, to perform mask/ no mask classification, a synthetic dataset is used to train a MobileNet-V2 classifier. This dataset contains images from both mask and no mask classes with nearly 1400 images. The masked faces are synthesized by artificially adding surgical face masks to normal faces. We will refer to this dataset as “SM-Synthetic (SurgicalMask-Synthetic)” throughout the rest of this post. Here is an example of the images from SM-Synthetic:

In the example from PyImageSearch, the MobileNet-V2 classifier was trained on SM-Synthetic with 99% accuracy on the validation set. However, in most real-world applications, the faces are far from the camera, blurry, and low resolution. Unfortunately, this dataset cannot help us solve the problem in such cases.
Moreover, currently available datasets for face mask classification only include a few face mask types. For example, the only face mask used in the SM-Synthetic dataset is a plain, white surgical mask. In practice, however, people use different kinds of face masks in every color and various shapes. A face mask classifier trained on the SM-Synthetic dataset fails to generalize well to different face masks due to the lack of diversity. In the following video, you can observe that the model fails to classify unseen face masks correctly:
Compare this demo with our final classifier:
At Galliot, we were curious about building a face mask detector that can generalize well to real-world data. We tried different datasets with several detectors and classifiers to come up with the right solution. In the following series of experiments, we will walk you through the evolutionary path that we followed to construct a real-world mask/ no mask dataset and build a face mask classifier that can also work well on real-world data.
For convenience, the details about all datasets that we will refer to throughout this post are listed in Table 1.
| Dataset Name | Dataset Size | Training Set | Validation Set | Description |
|---|---|---|---|---|
| SM-Synthetic | 1457 | Mask: 658 No Mask: 657 | Mask: 71 No Mask: 71 | Link to the dataset A surgical mask is synthesized on faces. |
| BaselineVal | 2835 | – | Mask: 1422 No Mask: 1413 | Collected from CCTV video streams with blurry, low-resolution images. |
| Extended-Synthetic / Extended-Synthetic-Blurred | 23K | Mask: 9675 No Mask: 10353 | Mask: 1206 No Mask: 1207 | Link To the dataset. Collected from WIDER FACE, CelebA, and SM-Synthetic. Fifty-four distinct face masks are synthesized for normal faces. |
| FaceMask100K | 100K | Mask: 50604 No Mask: 49417 | Mask: 1422 No Mask: 1413 | Collected from CCTV video streams with blurry, low-resolution images. Manually labeled by Galliot. |
3. Experiment #1: The First Shot
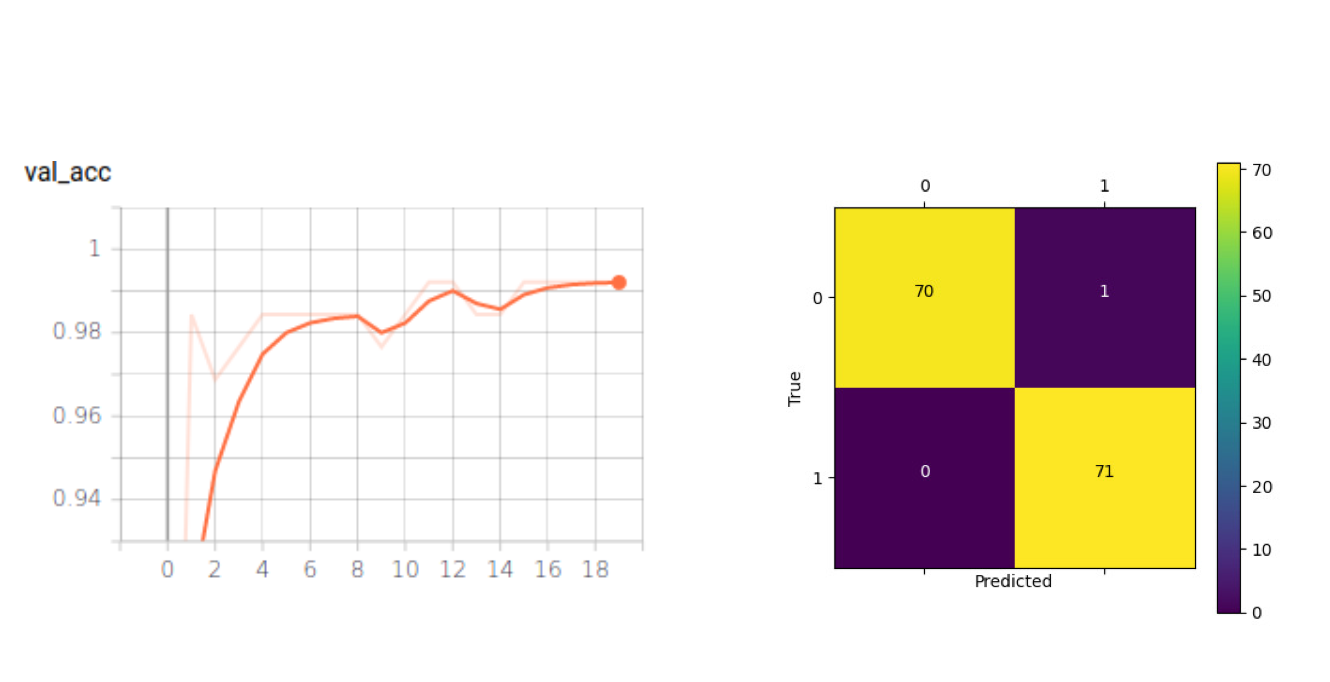
For the first experiment, we trained an SSD-MobileNet-V1 model to reproduce the work by PyImageSearch. The face detector was trained on WIDER FACE, a face detection benchmark dataset, and achieved a 67.93% mAP score on the WIDER FACE validation set. We used the SM-Synthetic dataset to train a mask/not mask MobileNet-V1 classifier that achieved 99% accuracy on the SM-Synthetic validation set.
Then, to cut the number of parameters used by the MobileNet-V1 classifier model (~3.5 M parameters), we started thinking about whether we could build a custom CNN model that can do the same task as well as the previous model using much fewer parameters. After some experiments, we created the optimized CNN model, called OFMClassifier (Optimized Face Mask Classifier), with ~296K parameters – about 12x fewer than the number of parameters in the MobileNet-V1 model. This model achieved 99% accuracy on the resized version of the SM-Synthetic validation set (see Figure 3) 8x faster than the MobileNet-V1 model on GeForce RTX 2070 Super (see Table 2).
| Classifier | Inference time (ms) |
|---|---|
| MobileNet-V1 | 9.7 |
| OFM-Classifier | 1.2 |
Since the OFMClassifier worked as well as the MobileNet-V1 model using much fewer parameters, we decided to choose this network over the MobileNet-V1 model for this experiment.
We will train this model on different datasets throughout the rest of this post. The network architecture is explained in more detail in the following section.
3.1. Network Architecture Details and Hyperparameters (for Experts)
The network architecture is illustrated in Figure 4. The OFMClassifier model has three convolutional blocks. Each block has two consecutive convolutional layers followed by a “max pooling” and a “dropout” layer. In the convolutional layers, padding is added to input data to preserve image resolution and spatial size. Also, batch normalization is applied to ensure network stability. We applied max pooling to reduce image resolution, and in the last layers, we used global average pooling instead of using the flatten layer to perform down-sampling with fewer features (128 instead of 11*11*128). Finally, two fully connected layers are added to the network for the purpose of mask/ no mask classification (mask/ no mask).
For all the experiments, we applied the “Adam” optimizer with a learning rate of 0.0002, and the loss function was categorical cross-entropy. We used a batch size of 16 and trained our network for 20 epochs.

3.2. A Note On the Network Input Shape
Detected faces are cropped out of the original image before being passed to the classifier; therefore, they are already small. If we wanted to use large input shapes, we had to enlarge the detected faces, which would result in losing some useful information (see Figure 5). Also, we could minimize the computations and achieve faster inference by keeping the image size small. Thus, we changed the input shape to 45*45 pixels before passing the images to the network.

3.3. Experiment #1: the results
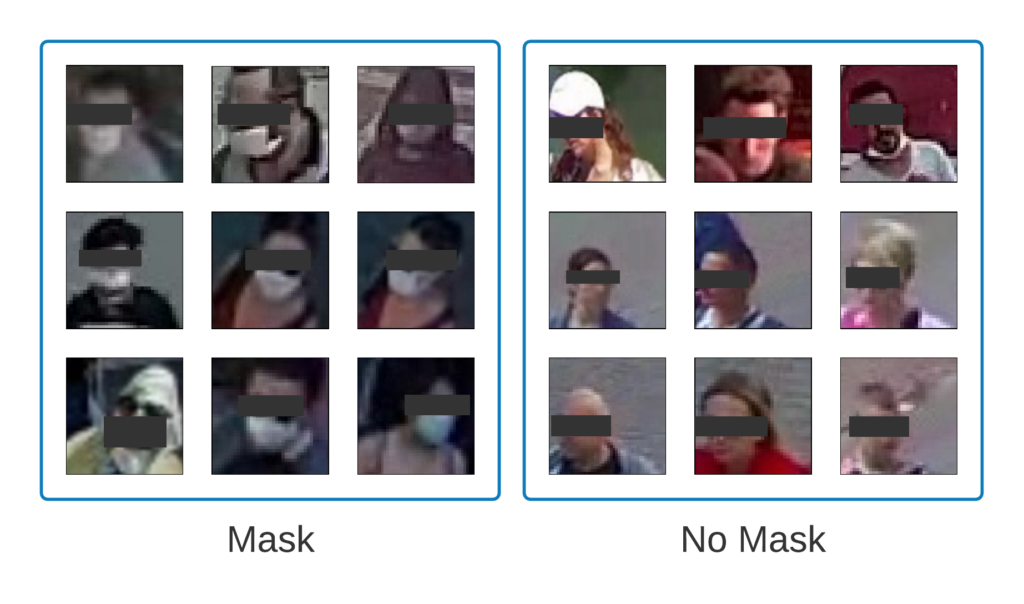
The model achieved 99% accuracy on the validation set, but don’t get too excited (yet)! To investigate if the OFMClassifier can generalize well to real-world data with blurry, low-resolution faces that are further from the camera, we constructed another validation set called BaselineVal. This dataset contains 2835 images belonging to two classes (mask/ no mask) collected from CCTV video streams. Figure 6 shows some examples from the BaselineVal dataset.
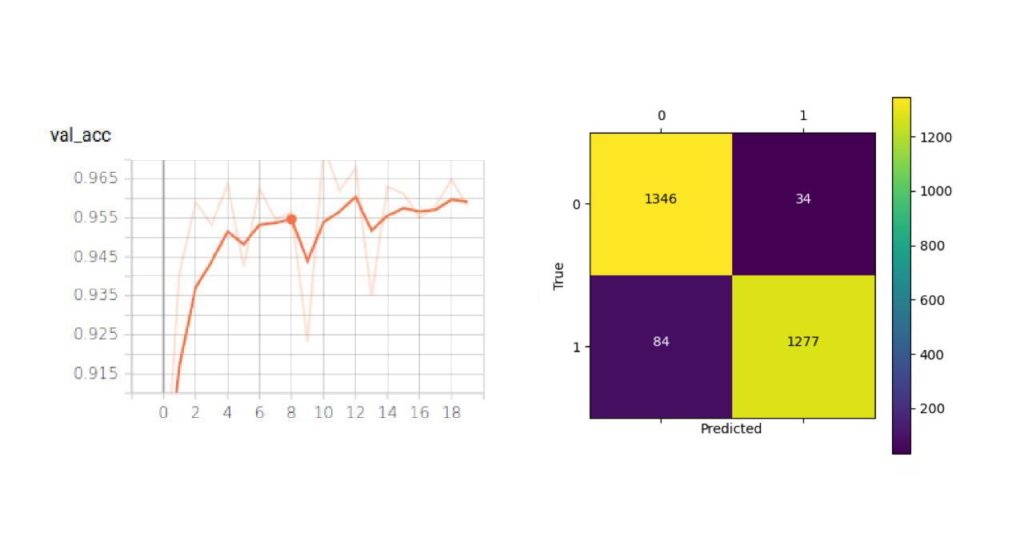
We tested the OFMClassifier on BaselineVal, and the model was degraded to an almost-random guesser with 62% accuracy. Figure 7 illustrates the new validation accuracy curve and the confusion matrix (compared with Figure 3).
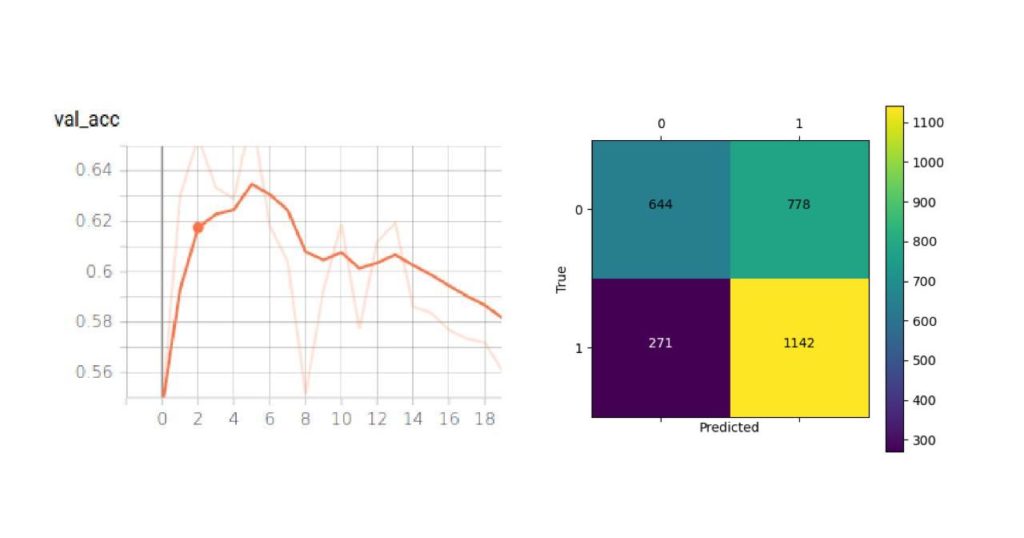
The OFMClassifier that worked well on the SM-Synthetic validation set failed to generalize to real-world data. We think that the main challenge is creating a more representative dataset with more diversity.
4. Experiment #2: The Extended-Synthetic Dataset
Following the previous experiment, we started synthesizing a new dataset from scratch, this time with more mask types in different colors and textures, to see if adding more diversity to face masks can improve model accuracy. We took normal face images from WIDER FACE, and CelebA artificially added face masks to these faces and added some images from the SM-Synthetic dataset to create the Extended-Synthetic dataset. The Extended Synthetic dataset is available for download here. Figure 8 illustrates the 54 different kinds of face masks that we used to build this dataset. A dataset of 54 different kinds of facemasks in .PNG format is available for download here. We also synthesized these face masks to 50K images from the CelebA dataset, which is available for download here.

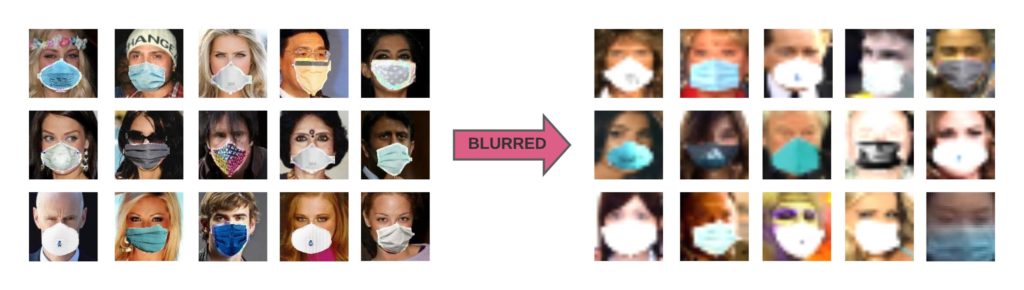
To make our dataset comparable to real-world scenarios, we blurred the faces from Extended-Synthetic to create a new dataset named Extended-Synthetic-Blurred with the same number of images in both training and validation sets. You can compare Extended-Synthetic-Blurred with Extended-Synthetic (not blurred) in Figure 9.
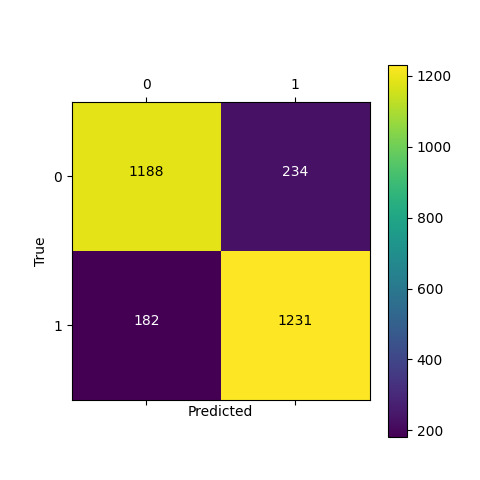
We used the SSD-MobileNet-V1 model from the previous experiment as the detector and trained an OFMClassifier on the Extended-Synthetic-Blurred dataset to classify the detected faces to mask/no mask classes. Figure 10 illustrates the validation accuracy curve and the confusion matrix for this experiment.
The model converged with 95% accuracy on the Extended-Synthetic-Blurred validation set.
To compare the classification accuracy between this model and the one from the first experiment, we also evaluated this model (trained on the Extended-Synthetic-Blurred dataset) on the BaselineVal dataset. The model outperformed the network trained on the SM-Synthetic dataset with 62% accuracy from experiment #1 (see Figure 7) and achieved 85% accuracy on the BaselineVal dataset.
We also tested this model on the demo video from experiment #1. You can see how adding images from several mask types to the training data can improve classification accuracy:
Furthermore, this model achieved a high accuracy of 96% when evaluated on the SM-Synthetic validation set. We can observe that this model outperforms the model from experiment #1 on BaselineVal while performing almost as accurately on the SM-Synthetic validation set.
Conclusion: Combining real-world data with blurred synthesized data that contains several mask types in different shapes, colors, and textures, increases model generalizability.
We trained a model on a synthetic dataset that achieved 95% accuracy on its validation set, which is pretty good. We also evaluated this model on the BaselineVal dataset –constituted of real-world data with no synthetic images– and the model obtained 85% accuracy. According to these results, we can conclude that the classification problem is more difficult with real-world data.
We examined the possible solutions to the mask/ no mask classification problem using synthetic datasets, but we were still looking for a production-level model trained on real-world data. Thus, we decided to manually annotate a dataset that represents real-world scenarios for mask/ no mask classification.
5. Experiment #3: FaceMask100K
We used several sources, such as videos from CCTV cameras, to construct a dataset with images representing real-world scenarios. The images were annotated with class names (mask/ no mask). The created dataset, called FaceMask100K, contains 98542 images in the training set and 2835 images in the validation set belonging to two classes (mask/ no mask).
Annotating this dataset required much effort. We collected videos from CCTV cameras captured in different places over several hours of the day and trimmed out those frames where a few people were passing by. Since the faces were too small in these videos, detecting faces was challenging, and common face detection approaches, such as training an SSD-MobileNet detector, did not work. Therefore, we used OpenPifPaf to detect faces and then extracted human heads (according to OpenPifPaf “Keypoints”) from these frames. Then, we manually annotated the detected faces to mask/ no mask classes. We will explain face detection challenges in CCTV video streams in more detail in part 2 of this series.
We trained a classifier on FaceMask100K that achieved 98% accuracy on the training set and 92% accuracy on the BaselineVal dataset, outperforming all the models from previous experiments. This model also achieved 97% accuracy on the SM-Synthetic validation set, 96% accuracy on the Extended-Synthetic validation set, and 95% accuracy on the Extended-Synthetic-Blurred validation set. Table 3 lists the datasets that we used to train the classifiers discussed in this post with their classification accuracy on the BaselineVal dataset.
| Training Dataset | Classification Accuracy on the BaselineVal Dataset |
|---|---|
| SM-Synthetic | 62% |
| Extended-Synthetic-Blurred | 85% |
| FaceMask100K | 92% |
6. Results
In the following table, you can see three face mask detectors by Galliot tested on different videos. The model trained on the Extended Synthetic dataset is the best when you want to detect face masks in videos with high quality, and the model trained on FaceMask100K is suitable for face mask detection on CCTV videos.
| Dataset Name | Demo Video #1 |
|---|---|
| Surgical Mask Synthetic | https://www.youtube.com/embed/a8C05FKbqQs |
| Extended Synthetic Blurred | https://www.youtube.com/embed/vRCeTMI4zeU |
| FaceMask100K | https://www.youtube.com/embed/pPEhfbskMTg |
| Dataset Name | Demo Video #2 |
|---|---|
| Surgical Mask Synthetic | https://www.youtube.com/embed/-lnacGf09WI |
| Extended Synthetic Blurred | https://www.youtube.com/embed/hvhc7dDpHMY |
| FaceMask100K | https://www.youtube.com/embed/M7wltRbEgIg |
| Dataset Name | Demo Video #3 |
|---|---|
| Surgical Mask Synthetic | https://www.youtube.com/embed/pWkexuP_IVs |
| Extended Synthetic Blurred | https://www.youtube.com/embed/Ti3Li4kvTmg |
| FaceMask100K | https://www.youtube.com/embed/n42lEDFkfbs |
7. Challenges
There are some cases in which our model has trouble classifying masked faces from unmasked ones correctly. For example:
– In some cases, the classifier changes its prediction for one detected face a few times. Adding a voting system or applying a tracker can improve the classification.

– We focused on creating a diverse training set. However, the training data does not have enough examples of some environmental conditions, such as lighting settings. For instance, there are not too many examples captured during the nighttime in the training set. Therefore, the model misclassifies some faces in videos captured at night. Adding more data to the dataset can improve classification accuracy in such cases.

– Our classifier struggles with classifying some face mask types. For example, red masks are often misclassified. Adding more face masks to the training data can fix this issue.

– The model cannot correctly classify masked faces from unmasked ones when the faces are too blurry, especially in cases where even a human cannot identify whether the person is wearing a mask or not.

– The model misses some faces and fails to classify face masks in videos that are captured from unseen angles. For example, the model cannot perform well in overhead angle views.

In future attempts, we will try to further improve our classifier and mitigate the mentioned challenges.
8. Conclusion
Because of data limitations, current approaches to building a face mask detector system are composed of two sections: the face detector and the mask/ no mask classifier. This post focused on training a mask/ no mask classifier that can work in real-world scenarios. In the next part, we will explain how to train a detector to detect small, blurry faces.
To train a mask/ no mask classifier, we started by training a model on an open-source synthetic dataset with much fewer parameters than a MobileNet model while preserving accuracy. Then, to add more diversity to the data, we created a new, larger dataset, called the Extended-Synthetic dataset, with 54 different mask types and blurred the faces to obtain Extended-Synthetic-Blurred. We trained a model on the blurred dataset, and the model outperformed the one from the previous experiment by a large margin. Then, to further improve our results and build a production-ready classifier, we built FaceMask100K, a large-scale dataset constituted of real-world mask / no mask images. We trained a CNN classifier on FaceMask100K that achieved 92% accuracy on the validation set and reported this model as our best face mask classifier. To the best of our knowledge, this model outperforms all the currently available face mask classifiers that can work on CCTV video streams. Our demo videos show that this model can work pretty well in real-world scenarios.
To facilitate continued work in this space, we have open-sourced the Extended Synthetic dataset. You can download the dataset by clicking on this link. Galliot’s face mask detection models are available for download on our GitHub repo. Select and download the model according to the platform you are using:
Refer to the second part of this article to learn more about the face detector we used in this application. Do not forget to check out our GitHub repo and other blog posts on our website to learn more.
License
This project is sponsored by Lanthorn. Visit Lanthorn.ai to learn more about our AI solutions.
All released datasets (Extended Synthetic dataset, Neuralet FaceMask50K dataset), released models, and Galliot’s GitHub source code are licensed under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.

Please reach out to us via hello@galliot.us or the contact us form if you need to use the datasets, model, or code base for commercial purposes; we are happy to help you!
Leave us a comment
Comments
Get Started
Have a question? Send us a message and we will respond as soon as possible.
I’m curious to find out what blog system you have been working with? I’m experiencing some minor security problems with my latest website and I’d like to find something more risk-free. Do you have any recommendations?