Quantization of TensorFlow Object Detection API Models

Image Source: https://www.deviantart.com/dnobody/art/8-Bit-Last-Supper-176002023
This tutorial explains approaches to quantization in deep neural networks and the advantages and disadvantages of using each method with a real-world example.
You can find Galliot’s Docker Containers and the required codes for this work in this GitHub Repo.
Along with optimization methods, high-quality datasets can make a huge difference in your deep learning model’s performance. Read more about Data Labeling Methods, Challenges, and Tools to create better datasets.
Check out Galliot’s other Services and Solutions.
In this tutorial, we will examine various TensorFlow tools for quantizing object detection models. We start off by giving a brief overview of quantization in deep neural networks, followed by explaining different approaches to quantization and discussing the advantages and disadvantages of using each approach. We will then introduce TensorFlow tools to train a custom object detection model and convert it into a lightweight, quantized model with TFLiteConverter and TOCOConverter. Finally, as a use case example, we will examine the performance of different quantization approaches on the Coral Edge TPU.
Quantization in Neural Networks: the Concept
Quantization, in general, refers to the process of reducing the number of bits that represent a number. Deep neural networks usually have tens or hundreds of millions of weights, represented by high-precision numerical values. Working with these numbers requires significant computational power, bandwidth, and memory. However, model quantization optimizes deep learning models by representing model parameters with low-precision data types, such as int8 and float16, without incurring a significant accuracy loss. Storing model parameters with low-precision data types not only saves bandwidth and storage but also results in faster calculations.
Quantization brings efficiency to neural networks
Quantization improves overall efficiency in several ways. It saves the maximum possible memory space by converting parameters to 8-bit or 16-bit instead of the standard 32-bit representation format. For instance, quantizing the Alexnet model shrinks the model size by 75%, from 200MB to only 50MB.
Quantized neural networks consume less memory bandwidth. Fetching numbers in the 8-bit format from RAM requires only 25% of the bandwidth of the standard 32-bit format. Moreover, quantizing neural networks results in 2x to 4x speedup during inference.
Faster arithmetics could be another benefit of quantizing neural networks in some cases, depending on different factors, such as the hardware architecture. As an example, 8-bit addition is almost 2x faster than 64-bit addition on an Intel Core i7 4770 processor.
These benefits make quantization valuable, especially for edge devices that have modest computing and memory but are required to perform AI tasks in real-time.
Quantizing neural networks is a win-win
By reducing the number of bits that represent a parameter, some information is lost. However, this loss of information incurs little to no degradation in the accuracy of neural networks for two main reasons:
1- This reduction in the number of bits acts like adding some noise to the network. Since a well-trained neural network is noise-robust, i.e., it can make valid predictions in the presence of unwanted noises, the added noise will not degrade the model accuracy significantly.
2- There are millions of weight and activation parameters in a neural network that are distributed in a relatively small range of values. Since these numbers are densely spread, quantizing them does not result in losing too much precision.
To give you a better understanding of quantization, we next provide a brief explanation of how numbers are represented in a computer.
Computer representation of numbers
Computers have limited memory to store numbers. There are only discrete possibilities to represent the continuous spectrum of real numbers in the representation system of a computer. The limited memory only allows a fixed amount of values to be stored and represented in a computer, which can be determined based on the number of bits and bytes the computer representation system works with. Therefore, representing real numbers in a computer involves an approximation and a potential loss of significant digits.
There are two main approaches to storing and representing real numbers in modern computers:
1. Floating-point representation: The floating-point representation of numbers consists of a mantissa and an exponent. In this system, a number is represented in the form of mantissa * base exponent, where the base is a fixed number. In this representation system, the position of the decimal point is specified by the exponent value. Thus, this system can represent both very small values and very large numbers.
2. Fixed-point representation: In this representation format, the position of the decimal point is fixed. The numbers share the exponent, and they vary in the mantissa portion only.
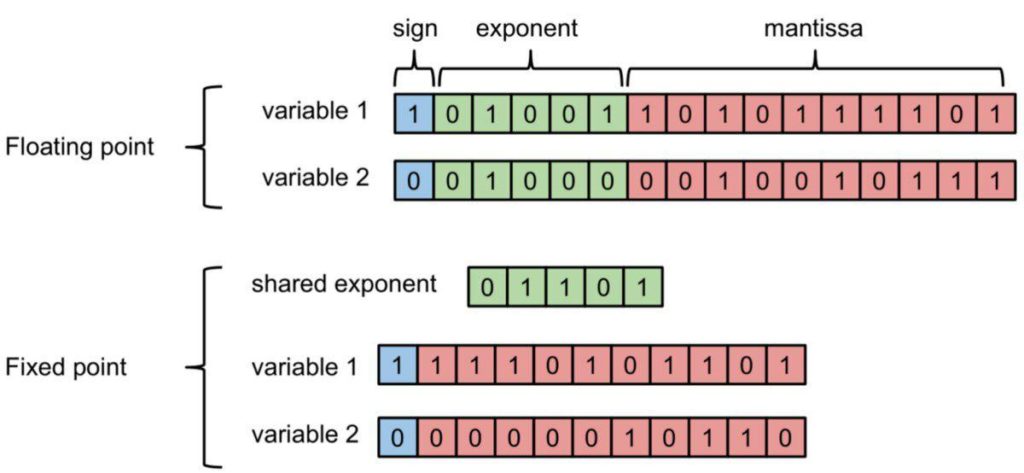
Figure 1. Floating-point and fixed-point representation of numbers (image source).
The amount of memory required for the fixed-point format is much less than the floating-point format since the exponent is shared between different numbers in the former. However, the floating-point representation system can represent a wider range of numbers compared to the fixed-point format.
The precision of computer numbers
The precision of a representation system depends on the number of values it can represent precisely, which is 2b, where b is the number of bits. For example, an 8-bit binary system can represent 28 = 256 numbers precisely. In this system, only 256 values are represented precisely. The rest of the numbers are rounded to the nearest number of these 256 values. Thus, the more bits we can use, the more precise our numbers will be.
It is worth mentioning that the 8-bit representation system in the previous example is not limited to representing integer values from 1 to 256. This system can represent 256 pieces of information in any arbitrary range of numbers.
How to quantize numbers in a representation system
When quantizing numbers in a representation system, some numbers are represented precisely, and some are approximated by the closest quantized value. To determine the representable numbers in a representation system with brr2b to find uk * uk = 0, 1, ..., 255rk -> k * uk * u(k + 1) * u
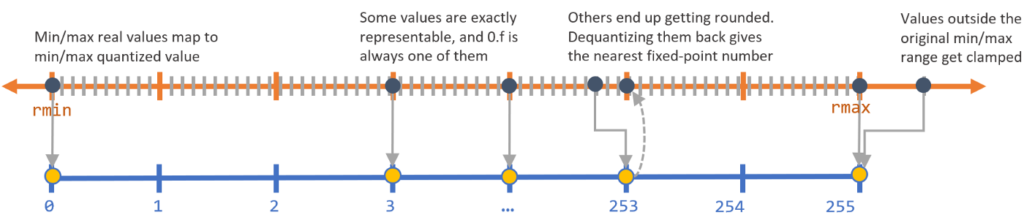
Figure 2. Quantizing numbers in a representation system (image source).
In the next section, we will explain how we can calculate the range of parameters in a neural network in order to quantize them.
How to quantize neural networks
Quantization is to change the current representation format of numbers to another lower precision format by reducing the amount of the representing bits. In machine learning, we use the floating-point format to represent numbers. By applying quantization, we can change the representation to the fixed-point format and down-sample these values. In most cases, we convert the 32-bit floating-point to the 8-bit fixed-point format, which gives almost 4x reduction in memory utilization.
There are at least two sets of numerical parameters in each neural network; the set of weights, which are constant numbers (in inference) learned by the network during the training phase, and the set of activations, which are the output values of activation functions in each layer. By quantizing neural networks, we mean quantizing these two sets of parameters.
As we saw in the previous section, to quantize each set of parameters, we need to know the range of values each set holds and then quantize each number within that range to a representable value in our representation system. While finding the range of weights is straightforward, calculating the range of activations can be challenging. As we will see in the following sections, each quantization approach deals with this challenge in its own way.
Most of the quantization techniques are applied to inference but not training. The reason is that in each backpropagation step of the training phase, parameters are updated with changes that are too small to be tracked by a low-precision data-type. Therefore, we train a neural network with high-precision numbers and then quantize the weight values.
Types of Neural Network Quantization
There are two common approaches to neural network quantization: 1) post-training quantization and 2) quantization-aware training. We will next explain each method in more detail and discuss the advantages and disadvantages of each technique.
Post-training quantization
The post-training quantization approach is the most commonly used form of quantization. In this approach, quantization takes place only after the model has finished training.
To perform post-training quantization, we first need to know the range of each parameter, i.e., the range of weights and activations. Finding the range of weights is straightforward since weights remain constant after training has been finished. However, the range of activations is challenging to determine because activation values vary based on the input tensor. Thus, we need to estimate the range of activations. To do so, we provide a dataset that represents the inference data to the quantization engine (the module that performs quantization). The quantization engine calculates all the activations for each data point in the representative dataset and estimates the range of activations. After calculating the range of both parameters, the quantization engine converts all the values within those ranges to lower bit numbers.
The main advantage of using this technique is that it does not require any model training or fine-tuning. You can apply 8-bit quantization on any existing pre-trained floating-point model without using many resources. However, this approach comes at the cost of losing some accuracy because the pre-trained network was trained regardless of the fact that the parameters will be quantized to 8-bit values after training has been finished, and quantization adds some noise to the input of the model at inference time.
Quantization-aware training
As we explained in the previous section, in the post-processing quantization approach, training was in floating-point precision regardless of the fact that the parameters would be quantized to lower bit values. This difference of precision that originates from quantizing weights and activations enters some error to the network that propagates through the network by multiplications and additions.
In quantization-aware training, however, we attempt to artificially enter this quantization error into the model during training to make the model robust to this error. Note that similar to post-training quantization, in quantization-aware training, backpropagation is still performed on floating-point weights to capture the small changes.
In this method, extra nodes that are responsible for simulating the quantization effect will be added. These nodes quantize the weights to lower precision and convert them back to the floating-point in each forward pass and are deactivated during backpropagation. This approach will add quantization noise to the model during training while performing backpropagation in floating-point format. Since these nodes quantize weights and activations during training, calculating the ranges of weights and activations is automatic during training. Therefore, there is no need to provide a representative dataset to estimate the range of parameters.
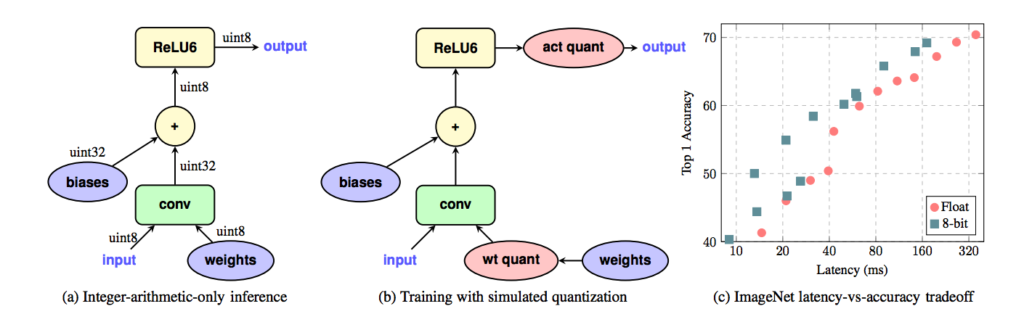
Figure 3. Quantization-aware training method (image source).
Quantization-aware training gives less accuracy drop compared to post-training quantization and allows us to recover most of the accuracy loss introduced by quantization. Moreover, it does not require a representative dataset to estimate the range of activations. The main disadvantage of quantization-aware training is that it requires retraining the model.
Here you can see benchmarks of various models with and without quantization.
Model Quantization with TensorFlow
So far, we have described the purpose behind quantization and reviewed different quantization approaches. In this section, we will dive deep into the TensorFlow Object Detection API and explain how to perform post-training quantization and quantization-aware training.
TensorFlow object detection API
The TensorFlow Object Detection API is a framework for training object detection models that offers a lot of flexibility. You can quickly train an object detector in three steps:
STEP 1: Change the format of your training dataset to tfrecord
STEP 2: Download a pre-trained model from the TensorFlow model zoo.
STEP 3: Customize a config file according to your model architecture.
You can learn more about each step in the TensorFlow Object Detection API GitHub repo.

Figure 4. TensorFlow Object Detection API (image source).
This tool provides developers with a large number of pre-trained models that are trained on different datasets, such as COCO. Therefore, you do not need to start from scratch to train a new model; you can simply retrain the pre-trained models for your specific needs.
Object Detection API offers various object detection model architectures, such as SSD and Faster-RCNN. We trained an SSD Lite MobileNet V2 model using the TensorFlow Object Detection API on the Oxford Town Centre dataset to build a pedestrian detection model for the Smart Social Distancing application. We picked the SSD architecture to be able to run this application in real-time on different edge devices such as NVIDIA Jetson Nano and Coral Edge TPU. We used ssdlite_mobilenet_v2_coco.config
Note that TensorFlow 1.12 or higher is required for this API, and this API does not support TensorFlow 2.
Installing TensorFlow object detection API with Docker
Installing Object Detection API can be time-consuming. Instead, you can use Galliot’s Docker container to get TensorFlow Object Detection API installed with minimal effort.
This Docker container will install the TensorFlow Object Detection API and its dependencies in the /models/research/object_detection
1- Run with CPU support:
- Build the container from the source:
# 1- Clone the repository git clone https://github.com/neuralet/neuralet cd training/tf_object_detection_api # 2- Build the container docker build -f tools-tf-object-detection-api-training.Dockerfile -t "neuralet/tools-tf-object-detection-api-training" . # 3- Run the container docker run -it -v [PATH TO EXPERIMENT DIRECTORY]:/work neuralet/tools-tf-object-detection-api-training
- Pull the container from Docker Hub:
docker run -it -v [PATH TO EXPERIMENT DIRECTORY]:/work neuralet/tools-tf-object-detection-api-training
2- Run with GPU support:
You should have the Nvidia Docker Toolkit installed to be able to run the docker container with GPU support.
- Build the container from the source:
# 1- Clone the repository git clone https://github.com/neuralet/neuralet cd training/tf_object_detection_api # 2- Build the container docker build -f tools-tf-object-detection-api-training.Dockerfile -t "neuralet/tools-tf-object-detection-api-training" . # 3- Run the container docker run -it --gpus all -v [PATH TO EXPERIMENT DIRECTORY]:/work neuralet/tools-tf-object-detection-api-training
- Pull the container from Docker Hub:
docker run -it --gpus all -v [PATH TO EXPERIMENT DIRECTORY]:/work neuralet/tools-tf-object-detection-api-training
Exporting the model to a frozen graph
After training the model, you can find the trained checkpoints, i.e., .ckptprotobuf file by freezing its computational graph. In general, you can use the export_inference_graph.pytfliteexport_tflite_ssd_graph.py
python3 object_detection/export_tflite_ssd_graph.py \ --pipeline_config_path=$CONFIG_FILE \ --trained_checkpoint_prefix=$CHECKPOINT_PATH \ --output_directory=$OUTPUT_DIR \ --add_postprocessing_op=true
Running this script will create a .pb$OUTPUT_DIR
Post-training quantization with TFlite Converter
As described earlier, post-training quantization allows you to convert a model trained with floating-point numbers to a quantized model. You can apply post-training quantization using TFlite Converter to convert a TensorFlow model into a TensorFlow Lite model that is suitable for on-device inference.
This API provides three options to quantize a floating-point 32-bit model to lower precisions:
1. quantize only weights to 8-bit precision
2. quantize both weights and activations to 8-bit precision
3. quantize only weights to floating-point 16-bit precision
We will investigate the first two approaches in this tutorial. Quantizing to floating-point 16-bit precision is beyond the scope of this article. Read this guide for more detail.
Weight quantization of a retrained SSD MobileNet V2
After exporting the model to a frozen graph, you can quantize the model weights by running the following Python script:
[1] import tensorflow as tf
[2] frozen_graph_file = # path to frozen graph (.pb file)
[3] input_arrays = ["normalized_input_image_tensor"]
[4] output_arrays = ['TFLite_Detection_PostProcess',
[5] 'TFLite_Detection_PostProcess:1',
[6] 'TFLite_Detection_PostProcess:2',
[7] 'TFLite_Detection_PostProcess:3']
[8] input_shapes = {"normalized_input_image_tensor" : [1, 300, 300, 3]}
[9]
[10] converter = tf.lite.TFLiteConverter.from_frozen_graph(frozen_graph_file,
[11] input_arrays=input_arrays,
[12] output_arrays=output_arrays,
[13] input_shapes=input_shapes)
[14] converter.allow_custom_ops = True
[15] converter.optimizations = [tf.lite.Optimize.DEFAULT]
[16] tflite_quant_model = converter.convert()
[17] with open(tflite_model_quant_file, "wb") as tflite_file:
[18] tflite_file.write(tflite_model_quant)
You only need to set the path to the frozen graph file and change the input shape. You can leave the rest of the code as it is.
In line 2.pb
In lines 3-8
In lines 10-13
Line 14allow_custom_ops14, you tell the TFLite Converter to find and quantize those registered custom operations. This line will raise an error in case of failure. Read more on custom operations and how to register them here.
In line 15
Finally, in lines 16-18.tflite
Note that in this method, TensorFlow Lite quantizes some of the activations dynamically in inference time in addition to weight quantization to improve model latency.
Full Integer Quantization of a Retrained SSD MobileNet V2
We now explain how to quantize the full network, including weights, activations, inputs, and outputs to 8-bit numbers.
Run the following script to perform full 8-bit quantization:
[1] import tensorflow as tf
[2] frozen_graph_file = # path to frozen graph
[3] input_arrays = ["normalized_input_image_tensor"]
[4] output_arrays = ['TFLite_Detection_PostProcess',
[5] 'TFLite_Detection_PostProcess:1',
[6] 'TFLite_Detection_PostProcess:2',
[7] 'TFLite_Detection_PostProcess:3']
[8] input_shapes = {"normalized_input_image_tensor" : [1, 300, 300, 3]}
[9] converter = tf.lite.TFLiteConverter.from_frozen_graph(saved_model_dir,input_arrays,
[10] output_arrays, input_shapes)
[11] converter.allow_custom_ops = True
[12] converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE]
[13] converter.representative_dataset = _representative_dataset_gen
[14] tflite_model_quant = converter.convert()
[15] with open(tflite_model_quant_file, "wb") as tflite_file:
[16] tflite_file.write(tflite_model_quant)
This script is similar to the last one, except that a representative_dataset
[1] import cv2
[2] import numpy as np
[3] from imutils import paths
[4] def _representative_dataset_gen():
[5] images_path = # path to represantative dataset
[6] if images_path is None:
[7] raise Exception(
[8] "Image directory is None, full integer quantization requires images directory!"
[9] )
[10] imagePaths = list(paths.list_images(images_path))
[11] for p in imagePaths:
[12] image = cv2.imread(p)
[13] image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
[14] image = cv2.resize(image, (300, 300))
[15] image = image.astype("float")
[16] image = np.expand_dims(image, axis=1)
[17] image = image.reshape(1, 300, 300, 3)
[18] yield [image.astype("float32")]
As you can see in this example, you should specify the path to sample images that represent the input data used in inference time. Based on our experience, a dataset of ~100 images would be enough for the TFLite Converter to reach an accurate estimate of the range of the activations.
Important Notes:
1. Those operations that are not supported by the TFLite Converter remain in floating-point after post-training quantization. If you want the converter to throw an error if an operation does not quantize, you should add the following line of code to your script: converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
2. If you want the converter to quantize the inputs and outputs of the model, add the following lines to the code:converter.inference_input_type = tf.uint8 & converter.inference_output_type = tf.uint8
Note that if you are quantizing your object detection model using the current version of the TensorFlow Lite Converter, adding these two lines of code will fail the quantization due to some compatibility issues.
Quantization-aware training with TensorFlow object detection API
You can use the TensorFlow Model Optimization Tool to perform quantization-aware training for Keras-based models. You can use this tool in either of two ways: 1- specify some layers to be quantized-aware, or 2- set the whole model to be quantized-aware. You can install this tool by following the installation guide here.
However, if you are using the TensorFlow Object Detection API to train your model, you cannot use TensorFlow Model Optimization Tool for quantization-aware training. This is because the current version of the object detection API requires TensorFlow 1.x, which is not compatible with the model optimization tool. To apply quantization-aware training for object detection models that are trained using the object detection API, you need to make some config changes.
If you take a look at the sample config files of the object detection API, you will notice some files that contain the quantized keyword in their name, such as the ssd_mobilenet_v2_quantized_300x300_coco.configgraph_rewriter
graph_rewriter {
quantization {
delay: 48000
weight_bits: 8
activation_bits: 8
}
}
By adding these lines to your config file, you tell TensorFlow that you want to perform quantization-aware training. The delay
The other two parameters specify the number of bits that weights and activations will be quantized to. Only 8-bit quantization is supported by TensorFlow at this time.
You can start quantization-aware training from a quantized or non-quantized pre-trained model checkpoint. See the object detection model zoo to explore object detection models and their checkpoints. For the pedestrian detection task, we used the ssd_mobilenet_v2_quantized_300x300_coco.configssd_mobilenet_v2_coco
After training has been finished, we can freeze the model and export the frozen graph by running the export_tflite_ssd_graph.py
TOCO
So far, we have trained a floating-point model by simulating the quantization effect in the training process, but we have not quantized the model yet. TensorFlow offers another tool that quantizes a model and exports it to a tflite
Based on TensorFlow documentation, to quantize your object detection model with TOCO, you need to build TensorFlow from the source. This can be a daunting procedure since it is time-consuming and may lead to environment inconsistencies that fail the build after a long process. To overcome this issue, we created an easy-to-use docker container. This container takes in the frozen graph file path and some other specifications as parameters and generates the tflite
Model quantization using the TOCO Docker container
To quantize your model using Galliot’s TOCO Docker container, you can either build the container from the source or pull the container from Docker Hub.
- Build the container from the source:
# 1- Clone the repository git clone https://github.com/neuralet/neuralet cd training/tf_object_detection_api # 2- Build the container docker build -f tools-toco.Dockerfile -t "neuralet/tools-toco" . # 3- Run the container docker run -v [PATH_TO_FROZEN_GRAPH_DIRECTORY]:/model_dir neuralet/tools-toco --graph_def_file=[frozen graph file]
- Pull the container from Docker Hub:
docker run -v [PATH_TO_FROZEN_GRAPH_DIRECTORY]:/model_dir neuralet/tools-toco --graph_def_file=[frozen graph file]
After running the container, you can find the quantized object detection model named detect.tflite in FROZEN_GRAPH_DIRECTORY
You can also customize other parameters when running the docker container. For example, you can override the default input shape and inference type by giving --input_shapes=[DEFAULT:1,300,300,3]--inference_type=[DEFAULT:QUANTIZED_UINT8]
Quantization Example: Coral Edge TPU
In this section, we deploy an object detection model on a Coral Edge TPU device to illustrate one of the applications of model quantization.
Edge TPU only supports 8-bit weights and activations; thus, we first need to quantize our model to 8-bit precision to be able to work with the device. We have described three strategies for quantizing an SSDlite MobileNet V2 model:
1. post-training quantization of weights
2. post-training quantization of weights and activations
3. quantization-aware training and quantization of weights and activations
Since Edge TPU requires 8-bit quantized parameters, the first strategy does not apply to these devices because activations remain in floating-point following this approach. We will now explain model quantization using the next two methods on an Edge TPU device.
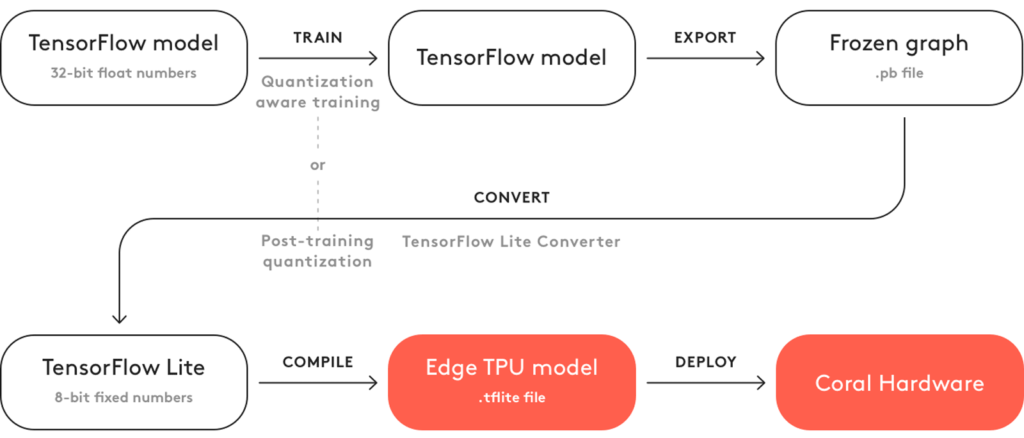
Figure 5. Steps required to deploy a TensorFlow model on edge TPU (image source).
To deploy a model on an Edge TPU device, you need to compile the quantized tflite
Operator Count Status
CUSTOM 1 Operation is working on an unsupported data type
ADD 10 Mapped to Edge TPU
CONCATENATION 2 Mapped to Edge TPU
QUANTIZE 11 Mapped to Edge TPU
CONV_2D 55 Mapped to Edge TPU
DEPTHWISE_CONV_2D 33 Mapped to Edge TPU
DEQUANTIZE 2 Operation is working on an unsupported data type
RESHAPE 13 Mapped to Edge TPU
LOGISTIC 1 Mapped to Edge TPUFor each operator, this log displays the operator name, the number of operators in the model, and the operator status, which indicates whether that operator is mapped to edge TPU or it will run on the CPU.
The log file for quantization-aware training is as follows:
Operator Count Status
CUSTOM 1 Operation is working on an unsupported data type
ADD 10 Mapped to Edge TPU
CONCATENATION 2 Mapped to Edge TPU
CONV_2D 55 Mapped to Edge TPU
DEPTHWISE_CONV_2D 33 Mapped to Edge TPU
RESHAPE 13 Mapped to Edge TPU
LOGISTIC 1 Mapped to Edge TPU
As you can see, the two DEQUANTIZE
Now we feed the Oxford Town Centre dataset to the compiled models and compute the latency and frame rate on the Coral Dev Board. The results are as follows:
| Quantization Approach | Inference Time [ms] | Frame Rate [FPS] |
|---|---|---|
| post-training quantization | 6.6 | 152 |
| quantization-aware training | 6.1 | 164 |
Visit Galliot’s GitHub repository for more examples of Edge TPU inferencing.
Conclusion
Quantization allows us to convert object detection models trained in floating-point numbers to lightweight models with lower-bit precisions. Quantized models accelerate calculations and consume less memory; therefore, they are ideal for edge computing applications.
In the Smart Social Distancing application, we have applied quantization to our pedestrian detection model to increase the speed of model inference and be able to run our application on different edge devices in real-time.
Visit Galliot’s GitHub repository for more projects. You can also reach us by email at hello@galliot.com.
A quick review of what we have explained in this article:
1- What is the Low-Bit Quantization of Neural Networks?
The process of reducing the bits that represent a number is called Quantization in general. When it comes to Deep Neural Networks (DNNs), we are talking about millions of high-precision numerical values (bits) as model weights. To process these gigantic amounts of numbers, we require significant computational power, processors, memory, and bandwidth. While quantizing our DNNs, we are actually optimizing our Deep Learning models by representing their parameters with low-precision data types such as int8 or float16 without causing significant accuracy loss. This optimization saves much bandwidth and storage and brings about faster calculations.
2- What are the upsides and drawbacks of Quantization in Neural Networks?
Upsides: It Saves Memory, Requires less Memory and Bandwidth, and yields Faster Arithmetic.
Downsides: Quantization lets a Noise enter the Neural Network that might affect and degrade the model’s accuracy. The noise is an error produced by low-precision arithmetic and approximations.
3- What are the differences between post-training quantization and quantization-aware training”?
Post-Training Quantization happens right after finishing the model’s training. Most significantly, it requires no model training or fine-tuning. Plus, you won’t need many resources to apply 8-bit quantization on an existing pre-trained floating-point model. However, due to adding some noise into the network, this approach costs you to lose some accuracy.
In Quantization-Aware Training, we anticipate and consider the error quantizing the weights may add to the network. Then, we try to artificially enter this error into the model during the training and make the model robust to this quantization error.
4- How to use TensorFlow tools to Train and Quantize an Object Detection model?
TensorFlow Object Detection API offers a lot of flexibility for training object detection models. This framework presents lots of pre-trained models trained on various datasets like COCO. So, instead of starting from scratch, you will be able to use its available models and retrain them based on your particular use case.
Since TFLite models are more appropriate for on-device inference, the TFLite Converter will allow you to apply post-training quantization and transform a TensorFlow model into a TFLite version.
To conduct Quantization-Aware training for Keras-based models, the TensorFlow Model Optimization is a practical tool for you.
TensorFlow offers another tool that quantizes a model and exports it to a tflite
5- How to convert an Object Detection model for Coral Edge TPU:
First, you should create a quantized TFLite version of the model. Note that since the Edge TPU only supports 8-bit integer arithmetic, full integer quantization should be performed on the model. Then you can compile this TFLite model for Edge TPU by Edge TPU Compiler (edgetpu_compiler
Further Readings
1- 8-Bit Quantization and TensorFlow Lite
This blog post explores the concept of 8-bit quantization and how it can be used with TensorFlow Lite to speed up mobile inference with low precision.
2- TensorFlow Object Detection API
This is the readme file of the TensorFlow Object Detection API repository on GitHub. The file contains information on how to use the API for training, evaluation, and deployment of object detection models.
3- Quantization Aware Training with TensorFlow Model Optimization Toolkit
The blog post explains how to use the TensorFlow Model Optimization Toolkit for Quantization Aware Training, which allows for training models with reduced precision to improve speed and decrease memory usage without losing accuracy.
4- TensorFlow Post-Training Integer Quantization
The post introduces the addition of post-training integer quantization to the Model Optimization Toolkit, a suite of techniques used to optimize machine learning models for deployment and execution. Integer quantization reduces the numerical precision of the weights and activations of models, improving memory and latency.
5- Quantization and Training of NNs for Efficient Integer-Arithmetic-Only Inference
The article proposes an on-device inference scheme that uses integer-only arithmetic to improve efficiency and reduce computational costs. The improvements were tested on MobileNets and demonstrated in ImageNet classification and COCO detection on popular CPUs.
Leave us a comment
Comments
Get Started
Have a question? Send us a message and we will respond as soon as possible.
Nice post. I learn something totally new and challenging on websites
Cool that really helps, thank you.
Good post! We will be linking to this particularly great post on our site. Keep up the great writing
Cool that really helps, thank you.
I like the efforts you have put in this, regards for all the great content.
You’re so awesome! I don’t believe I have read a single thing like that before. So great to find someone with some original thoughts on this topic. Really.. thank you for starting this up. This website is something that is needed on the internet, someone with a little originality!
I like the efforts you have put in this, regards for all the great content.
I think this post makes sense and really helps me, so far I’m still confused, after reading the posts on this website I understand.
You’re so awesome! I don’t believe I have read a single thing like that before. So great to find someone with some original thoughts on this topic. Really.. thank you for starting this up. This website is something that is needed on the internet, someone with a little originality!
I am truly thankful to the owner of this web site who has shared this fantastic piece of writing at at this place.
Nice post. I learn something totally new and challenging on websites
Good post! We will be linking to this particularly great post on our site. Keep up the great writing
Pretty! This has been a really wonderful post. Many thanks for providing these details.
This is my first time pay a quick visit at here and i am really happy to read everthing at one place