A Guide to Data Labeling Methods, Challenges, and Solutions
As AI systems become more complex, Data Labeling has become an inevitable stage in developing most AI and Machine Learning-related applications. But what is data labeling? and how is it done?
Note that this article requires familiarity with the basics of Machine Learning; If you are not familiar with these basics, you can learn them from provided links below:
1) What is Deep Learning?
2) Basic Concepts in Machine Learning by Jason Brownlee
3) Supervised vs. Unsupervised Learning by IBM Cloud
4) Supervised Learning by IBM Cloud Education
5) Machine Learning Fundamentals by Javaid Nabi – Medium
Find the list of 25 Popular Data Labeling Tools list along with important features and info to consider before choosing a tool for your project on:
– Top 25 Data Labeling Tools Landscape 2023
1. Introduction
Let’s begin our topic with some omnipresent use cases of AI. You have most definitely used at least one of the smart digital assistants like Siri, Google Assistant, and Alexa. It is awesome that you can actually speak out your commands, and they will take that action for you. When you tell Siri to “play some music,” she starts sifting the background noises and interpreting and executing your command.
Another amazing use case of AI is in self-driving cars. Using the power of AI, these cars can identify pedestrians, objects, and other vehicles and understand the signposts in real-time. So they can automatically control the vehicle without any interference from the passenger.
A huge portion of our AI problems is addressed using supervised machine learning. Therefore, this vast number of use cases of AI will not be feasible without having labeled data.
Many ML engineers and data scientists only focus on optimizing the algorithms to increase their model’s performance. This is while data labeling/data annotation has a critical impact on developing a high-performance machine learning model on an industrial scale. They might think the labeled data is easily available; however, data gathering and labeling for supervised learning algorithms are among the most laborious tasks in big industrial or production-level projects. This is a crucial phase that needs intelligent decision-making and management. Thus, poor planning can lead to the project’s failure and impose high financial and time costs on the company.
In this article, we aim to talk about data annotation, its challenges, methodologies, and intelligent approaches that can ease and speed up this process. We also provide a list of popular data-labeling tools and diagrams representing each tool’s supported data types, features, and tasks.
Data Labeling Complexities
When working on mission-critical applications such as self-driving cars or medical diagnosis models, you should create; 1) precise labels with minimum error and 2) a dataset considering various conditions and cases for model generalization.
Imagine you are building a human detection model for self-driving cars. In this case, you should ensure having labeled data for different lighting (day or night), weather conditions, camera angles, etc. Otherwise, a false detection can even cause loss of life.
In medical use cases such as labeling the X-ray images, you can not rely on regular data annotators (labelers) for the job. For this purpose, you should employ experts that can precisely determine the labels based on the target disease. So, finding a workforce with such specialty and high costs can increase the complexity of the process.
2. Data Labeling Approaches
There are several approaches for solving your data labeling (also known as data annotation) problems. Since each method has its own advantages and disadvantages, companies should undergo a detailed assessment phase using various factors to determine the best labeling approach based on their project’s scope, size, and duration.
Here we have mentioned some of the most common methods for labeling data with a short explanation of each one:
2.1. In-house Labeling
In this approach, companies should gather a data labeling team using their data scientists and ML engineers. Internal data scientists and experts know the problem and its complexities and hence understand the use case of their dataset. So, their labels (created datasets) are more suitable for the project compared to other labeling approaches. Consequently, companies use their internal data scientists to increase the quality and accuracy of labeling and make it easier to track. However, this method is time-consuming and requires extensive resources. Plus, it engages expensive company employees such as data scientists and ML engineers for simpler tasks. Therefore, this method can be suitable for different companies based on their project’s size, duration, and available infrastructures. You can see an approximate diagram in Figure 1.
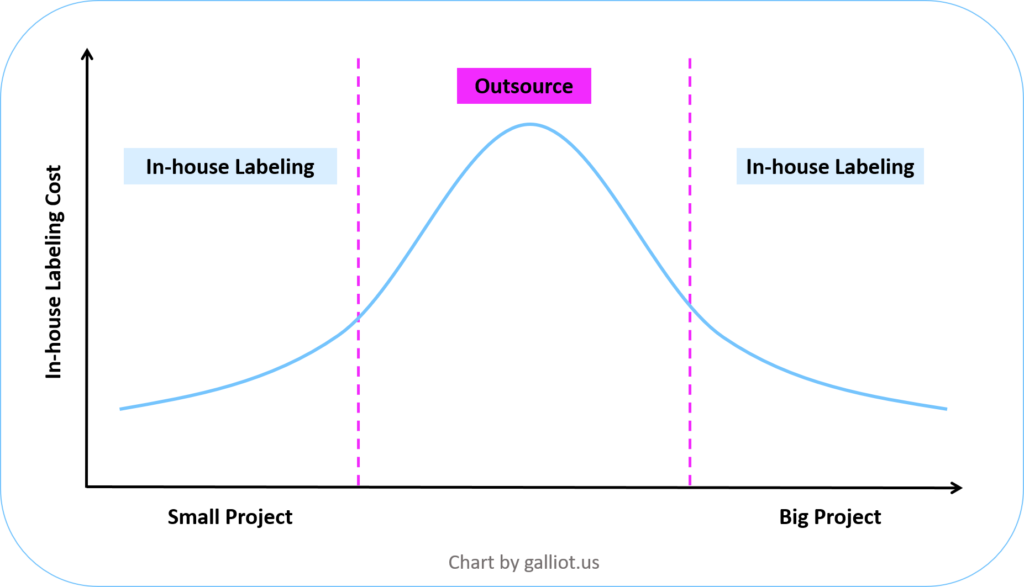
Figure 1. Project size and In-house data labeling cost trade-off. Outsource labeling is more beneficial in the zone between the dotted lines.
2.2. Outsourcing
Gathering and managing a team of freelancers will be challenging and time-consuming. If you have a temporary project that does not require constant improvement, this method can be efficient for you. In this practice, companies hire outside teams specially trained for manual data annotation. Companies like Scale AI or AILabelers.com can handle hiring and managing people for data labeling. Moreover, most freelancing platforms offer data labeling teams with pre-vetted staff and tools for data labeling.
Outsourcing is a good way for companies to save money and time compared to in-house labeling. Using outside labeling teams is very fit for projects that need labeling large amounts of data in a short time.
Still, this method has its cons; for instance, your ML engineers have much lower control over the labeling workflow compared to internal labeling. Note that this statement might not be true all time; using a “hybrid internal and external workforce,” you can have more control over the process. In this scenario, you can have your tools and workflow and hire outsourced resources to do the manual job.
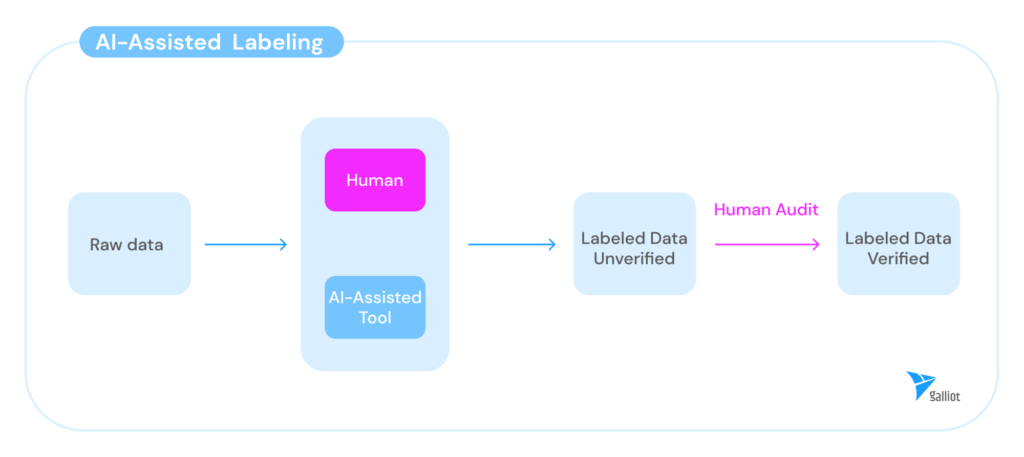
2.3. Automated Labeling
Currently, there are various AI-powered data annotation tools that can automatically annotate and prepare the data for further labeling. These tools usually use pre-trained AI models to detect and annotate the elements of interest in a new dataset. For example, they use a pre-trained object detection model to annotate various objects in the images of a dataset.
Another type of these tools uses AI modules to assist the annotators and ease the labeling process. The AI modules can learn from the annotator’s pattern and start annotating the data autonomously. They can provide significant assistance to annotators and optimize the process.
For example, Snorkel AI offers programmatic labeling and data-centric workflows to accelerate AI development. Snorkel Flow is a data-centric platform for building AI applications to make programmatic labeling accessible and performant.
2.4. Crowdsourcing
Crowdsourcing is a faster and more cost-efficient approach to your data labeling problem. Similar to outsourcing, there are many crowdsourcing platforms that assign your data labeling tasks to freelancers from around the world. This way, you can eliminate employing hundreds of temporary employees, invest in annotation tools, and micro-manage the team. Moreover, using a multinational workforce can reduce the risk of bias. However, in this method, quality control is not guaranteed, and you may not achieve consistent results over time.
Scale and Amazon Mechanical Turk are two of the most popular crowdsourcing platforms for data gathering and annotation. There are also some specialized vendors for domain-specific data annotation services. iMerit is one of the platforms offering data annotation services for specific industries.
2.5. Synthetic Data
This approach uses pre-existing datasets to generate data for a new project. Synthetic data is scalable, improves data quality and balance, and significantly reduces the time required for data gathering. On the other hand, you should consider the extensive computing power needed for this task, which can increase the project’s costs.
You can find an example of generating and implementing synthetic data in our Edge Face Mask Detection application. In this project, we have used a synthetic method to generate a labeled face mask dataset.
| Labeling Method | In-House | Outsourcing | Automated | Crowdsource | Synthetic |
|---|---|---|---|---|---|
| Time Required | High | Average | Low | Low | Low |
| Cost | High | Average | Low | Low | Low |
| Labels Quality | High | High | Average-Low* | Low | Average |
| Security** | High | Average | High | Low | High |
* Depending on the type of automation, it can vary.
** Security refers to keeping the data safe and avoiding data leakage.
2.5. Hybrid Labeling Approaches
Hybrid methods can be a combination of all or some of the approaches mentioned above. They can be applied based on the company’s resources and their projects’ duration and goals. A hypothetical pipeline for a hybrid method can be like this:
1- Start with an AI Data Labeling tool
2- Crowdsource
3- External experts
4- Internal experts
3. Data Labeling Methodology
Every company might have a different methodology to solve its data labeling problem. We will present the experience of our friends working in large companies and ourselves. So, what we say in this blog is not the absolute truth. To start the data labeling process, you need to define the ontology of your labels. To do this, you can prepare a handbook to describe your use case and requirements and determine the ontology of your labels.
After defining your labels and what you expect of your data, you should follow these steps:
1- Create an instruction and workflow
Preparing a notebook that defines the labels, states the project’s details and expectations, and how to use the tool to label data and submit the labels.
2- Prepare infrastructure
Specifying where to store the data, e.g., cloud, in-house server, distributed storage, etc. Then you should prepare the required infrastructure for chosen data storage.
3- Setting up the tools
Select, provide, and set up the labeling tools you are going to work with, such as Labelbox, Label Studio, etc.
4- Labeling (Annotation)
Annotators start labeling the data using provided tools.
5- Assessment
Using data assessment methods, you should determine if labels have the desired quality or not.
4. Data Labeling Challenges and Solutions
Each data annotation/labeling method has its cost and challenges for a company. These challenges may vary depending on the company’s approach to this task, but in particular, the following items are some of the most common ones:
1- Cost
2- Time or Speed of Labeling
3- Quality of Labels
Data labeling is an expensive and time-consuming task. There are various ways to speed up the process, but it will affect the quality and cost of labeling. For example, increasing the number of annotators/labelers can save time, but it will decrease the consistency of the labels. Furthermore, almost all labeling approaches are prone to human errors. These errors can happen in the manual entry or coding phase, decreasing the quality of labeled data. We should also mention “Bias” in data labeling, which is a serious issue in AI nowadays.
As you can see, there is a very tight correlation between these challenges. So, companies should know about the various solutions and consider their use case and requirements to find the best answer.
4.1. Semi-automated Labeling
This method uses a combined system for labeling the data. It employs a pre-trained model (on a similar dataset) for assisting the human labeler/annotator. This model can also learn from the annotator’s decisions, suggest labels, and automate the basic functions of the labeling platform.
Using semi-automated labeling approaches can significantly reduce the project’s time and costs. However, the quality of labels can vary depending on the model’s accuracy and level of automation.
4.2. Multi-layer Labeling
Multi-layer labeling employs three labeling phases for the process; at the early level, we use pre-trained AI models for an automated annotation phase. Then we hire less-expensive workforces for quality control and labeling the provided labels in the previous step. Finally, we can recruit expensive domain specialists (experts) to do the final labeling round for us. This way, we can manage our financial and computational resources logically.
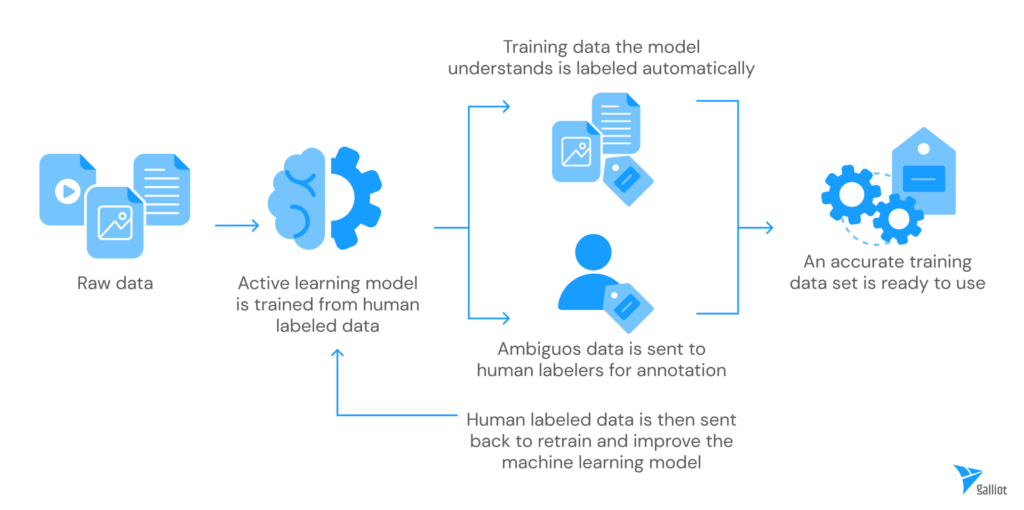
4.3. Active Learning
Active learning is a semi-supervised machine learning method that helps us label a set of data. In this procedure, we only need to target a small and important subset of available data for manual labeling. Using these manually labeled data, we train an AI model and run it on the remaining data to automatically infer their labels. After running the model, it will provide another subset of data in addition to the labels. These data are usually the ones that were more difficult to predict or had more uncertainty for the model. As a result, we have another valuable subset of the data to start labeling manually. Now, combining these two subsets of (labeled) data, we can go for another round of training and labeling.
Moreover, While re-labeling the provided subset of data, we can see if the labels match the actual value. This way, we can assess the model’s performance in each iteration. Therefore, only by manually labeling a small portion of the data we will have high-quality labels after a few iterations.
4.4. Quality Control
To ensure our data quality, we need to set up a series of measurements to assess and improve our labels’ quality. There are different methods to improve the quality of labels. For example, we can give specific data to multiple labelers and accumulate the results. We can also use the data we already know about their tags to compare the results with actual labels to measure our labels’ quality.
5. Data Labeling / Data Annotation Tools
If you have decided to roll up your sleeves and start in-house labeling, there are several tools in the market to help you in this process. Considering your project’s size, type, and requirements, you should compare and choose between these data labeling (annotation) platforms. By the way, we have mentioned a few tips based on our experience that might help you select a more suitable data annotation/labeling tool.
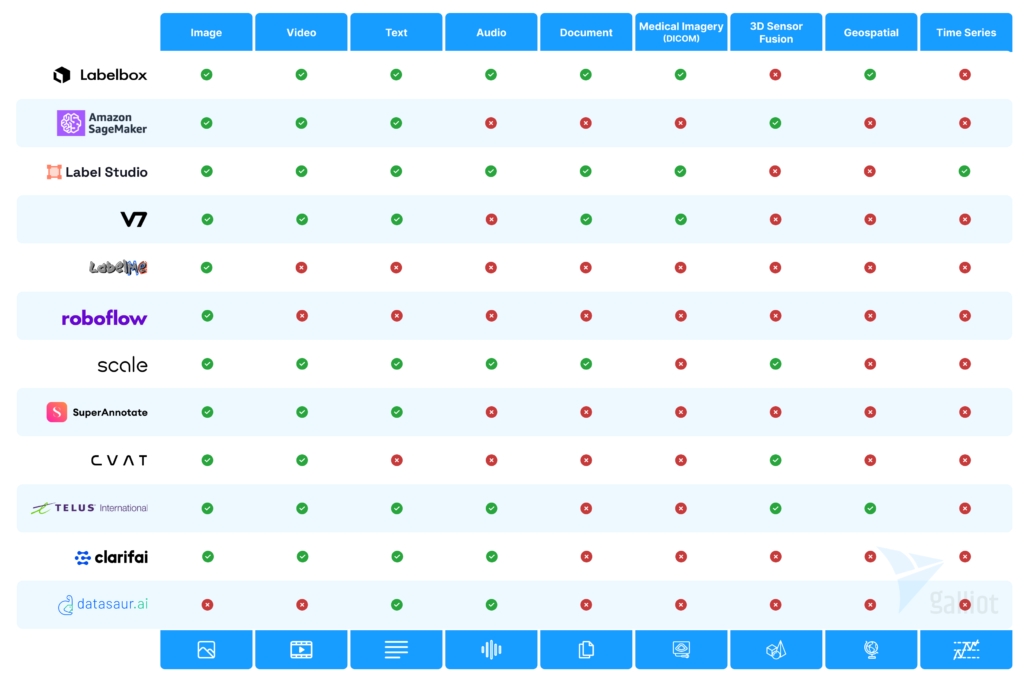
You should know that most labeling tools offer simple drawing features and a user-friendly graphical interface. As shown in the diagram below, almost all of these labeling tools accept image and video data. However, your project may need a more complicated type of annotation, like the segmentation of CT scan images. Also, your data modality might be of another kind, such as audio, text, time series, etc. So, while choosing a labeling platform, you must consider these requirements.
For example, imagine you need segmentation for pathological images. In this case, you should see if the data annotation platform supports medical imagery data (DICOM) while it offers segmentation tasks. In the following diagram, you can find the supported data modalities of some popular data labeling tools. You can also find a comprehensive chart of labeling platforms and their supported tasks at the end of this article (figure 7).
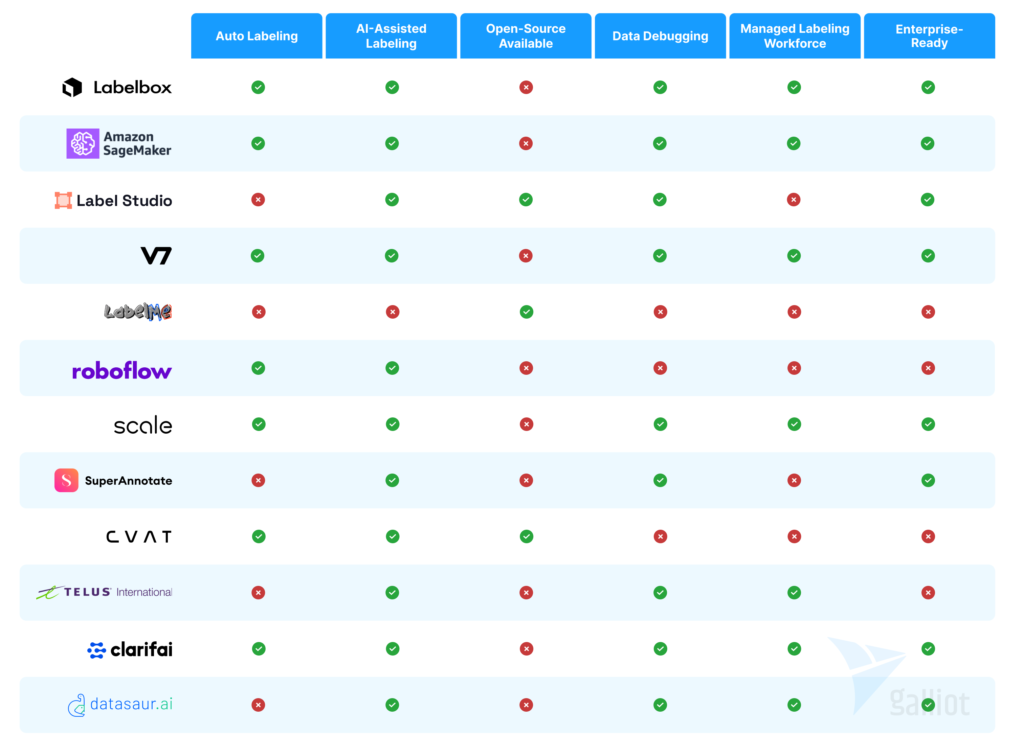
In production, you will need tools that can assess your model so you can find the deficiencies of your model. Visualization tools can help you see your model’s behavior for evaluations like confidence assessment. For example, you can find out if your model does not work well in certain conditions, like images taken at night. The below diagram shows some of the most important features to be considered for choosing a data labeling tool for your company.
If you search the web for data labeling/data annotation tools, you will find several websites comparing these tools. Here are some good examples of these tools you can use in your projects:
As we mentioned earlier, Labelbox is one of the most comprehensive data labeling platforms with several features for various use cases. Amazon SageMaker Ground Truth offers a state-of-the-art data labeling service that helps you find raw data, add labels, and implement them in your ML model. You can also find Label Studio’s open-source data labeling tool very useful for your projects.
5.1. Popular Data Labeling Tools:
1- Labelbox: A cloud-based data annotation platform that supports a wide range of data types and provides collaboration and quality control features.
2- Amazon SageMaker Ground Truth: A fully managed data annotation service that uses machine learning to reduce the cost and effort of manual annotation.
3- Label Studio: An open-source data annotation tool that allows teams to create custom workflows and manage projects in one place.
4- V7 Labs: It provides a wide range of labeling solutions, from image and video annotation to auto annotation and dataset management for different industries.
5- LabelMe: An open-source online annotation tool for creating image databases.
6- SuperAnnotate: It is a cloud-based AI-powered image annotation tool. It offers high-speed and high-quality image labeling services for various use cases, including computer vision, self-driving cars, and medical imaging. It provides various annotation tools and supports collaboration with team members.
7- Roboflow: A computer vision platform that automates and speeds up the data annotation process.
8- LionBridge AI: A provider of data annotation and artificial intelligence services for various industries, including healthcare and retail.
9- Amazon Mechanical Turk: A marketplace for businesses and individuals to outsource small tasks to a global workforce.
10- CVAT: It is a tool developed by Intel for annotating and labeling datasets for computer vision tasks such as object detection and image segmentation. It provides a web-based interface for annotation and allows collaboration between multiple annotators.
11- VOTT: A free, open-source tool for creating and managing object detection datasets.
12- Dataturks: A platform for data annotation and labeling services, including image and video annotation.
13- Playment: A data annotation platform that offers quick turnaround times and a large pool of annotators.
14- Clarifai: A deep learning platform that provides image and video recognition and annotation services.
15- Datasaur: A cloud-based platform for scalable and efficient data annotation, including computer vision and natural language processing tasks.
16- Dataloop: An AI-assisted data labeling platform that enables users to label data and train machine learning models, with a focus on improving speed and accuracy.
17- Alegion: A data annotation company that provides manual data labeling services for a variety of industries, including computer vision, natural language processing, and speech recognition.
18- LightTag: A text annotation tool that enables users to label text data for NLP tasks and quickly train machine learning models.
19- Prodigy: An annotation platform that enables users to label data and train machine learning models, with a focus on active learning and collaboration.
20- iMerit: It is a platform that provides data annotation services to various industries such as technology, retail, healthcare, and others. It offers a wide range of annotation services, such as image annotation, text annotation, video annotation, and audio annotation.
6. Beyond Data Labeling – Enabling Trustworthy AI Models with Better Data
6.1. Error Analysis
Many of us think that data labeling is all about indicating certain elements in given data for a specific task. For example, annotating individuals’ location in an image for a person detection task. However, working at the production level, we need to perform an error analysis phase after training a model. The error analysis specifies our model performance in different situations. For instance, in an object detection problem, these situations are different camera angles, different image lighting (day or night), the distance of objects from the camera, etc. Adding these parameters to our labels as metadata will significantly help us in the model’s error analysis.
6.2. Model Card
By considering these extra parameters (metadata), we will know more clearly the situations in which our model has a good or bad performance. Therefore, we can prepare and enclose a Model Card when shipping our model to increase its transparency. Model Cards are something like a drug prescription, including the instructions for using the model, explaining its limitations, and the best and worst situations of using it.

6.3. Datasheet for Datasets
In addition to Model Cards that increase the transparency of the model, there is a similar concept for datasets called “Datasheet”. Using datasheets, we create a comprehensive documentation of various steps and the process of creating a dataset. This way, the dataset’s creators help the consumers know if it is the right choice for their use case, uncover any unintentional source of bias, etc.
Consequently, to increase transparency in your work, we suggest you consider the points mentioned above for better communication with your colleagues or external customers.
7. Conclusion
Data labeling, or data annotation, has become an inevitable stage in the development of most AI and machine learning-related applications. Developing AI (especially Deep Learning) algorithms need an adequate amount of data. The more data the AI engine has, the more accurate it becomes.
In this article, we introduce the basic concepts related to different data labeling approaches and briefly explain the principles and limitations of each labeling method. We discussed the labeling’s cost, time, and quality challenges and introduced some available solutions for these challenges. We also listed the popular data annotation tools, providing a reference for readers who are interested in this field.
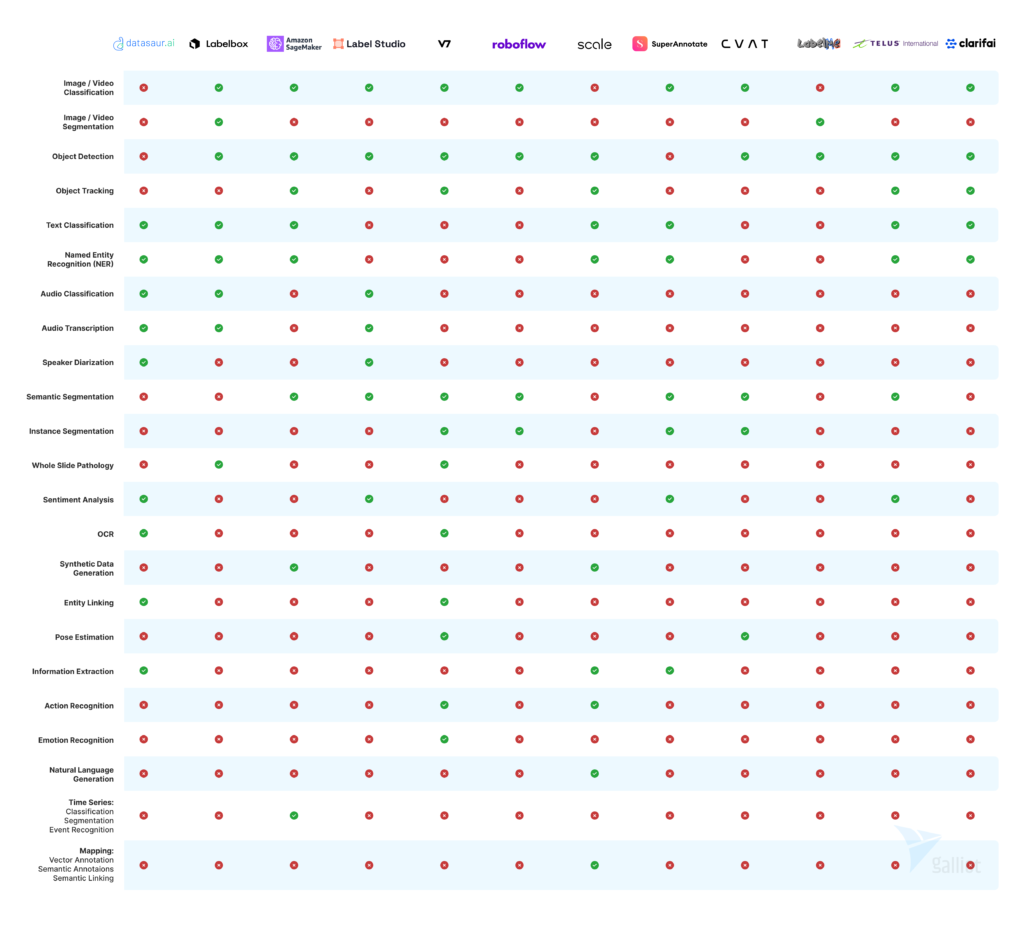
Below is a comprehensive table showing various features of data labeling platforms. Using this diagram, you can compare and choose the best annotation tool for your project.
If you are interested in adopting AI in your business, contact us using the “Contact” section below or directly email us at hello@galliot.us for consultation.
Get Started
Have a question? Send us a message and we will respond as soon as possible.
Leave us a comment