Adaptive Learning Deployment with NVIDIA DeepStream

Here we briefly described how we deployed our Adaptive Learning object Detection Model on X86s and Jetson devices using NVIDIA DeepStream and Triton Inference Server.
If you are starting with DeepSream and want to know what is a Pipeline, Element, Pad, Probe, Metadata, etc., you can refer to the other parts of these series:
Part 2: NVIDIA DeepStream Python Bindings; Customize your Applications
Part 3: An NVIDIA DeepStream Python Bindings Example; Building a Face Anonymizer
Visit our guide to Data Labeling Approaches and Challenges for building high-quality datasets.
1. Introduction
There are many cameras and other data resources constantly capturing video streams that can be useful for solving real-world challenges or improving revenue streams. Whether we are building an application for parking management, defect detection in a factory, managing logistics, traffic control, or occupancy analysis, every application needs reliable, real-time Intelligent Video Analytics (IVA).
DeepStream is a tool for building end-to-end AI-powered services and solutions for transforming video frames, pixels, and sensor data into actionable insights. It is a streaming analytic toolkit that takes the streaming data as input and uses AI and computer vision to generate insights from pixels for a better understanding of the environment (Nvidia). Using DeepStream coupled with NVIDIA Triton Inference Server, you can take your trained model from your desired framework, such as TensorFlow, TensorRT, PyTorch, or ONNX-Runtime, and directly run inferences on streaming video.
2. DeepStream Vs. Other tools
Despite other tools such as Gstreamer and OpenCV, DeepStream features hardware-accelerated building blocks, called plugins, that bring various processing tasks, such as video encoding and decoding, into a stream processing pipeline. Running the whole pipeline on GPU instead of CPU (Gstreamer & OpenCV) eliminates the data transfer overhead between CPU and GPU. It is easier for batching and running parallel tasks and significantly accelerates processing. DeepStream is easily scalable and suitable for multiprocessing. It runs concurrently for multiple sources and sinks and is flexible for rapid prototyping and full production-level solutions. Consequently, you can achieve real-time performance using DeepStream.
3. Our Story
We have recently developed a solution that creates specialized lightweight object detection models that adapt to new environments and datasets without any need for data labeling, called Adaptive Learning. The output of adaptive learning is a TensorFlow SSD-MobileNet-V2 model, which you need to deploy on your system to stream a video and run the model inference on the video stream.
To find the best solution for deploying our video analytic object detection tool, we have tried different pipelines. First, we used OpenCV to prepare a prototype quickly. However, it imposed a huge overhead, especially working with edge devices; hence we decided to use the DeepStream because of the reasons mentioned earlier.
In the following, we explained how we could deploy our Adaptive Learning Object Detection output models on X86s and Jetson devices using DeepStream.
3.1. Deploying Adaptive Learning on X86 using DeepStream and Triton Inference Server
TensorFlow models are not natively supported by DeepStream. So, to run our trained models on X86 nodes with connected NVIDIA GPU using DeepStream, we should use a middleware that can directly deploy various models from different frameworks, such as TensorFlow, on DeepStream. Before introducing DeepStream 5.0, performing computer vision tasks with DeepStream required converting the model to TensorRT. The DeepStream 5.0 integrates Triton Server directly from the application, which provides you with the flexibility of using common deep learning frameworks with DeepStream. This also enables you to prototype the end-to-end system quickly.
Since our object detection model output is in TensorFlow Protobuf format, we also used Triton Inference Server to deploy it directly on X86. There are five steps for deploying the models on deep stream using the triton inference server as follows:
Note that the following steps are different in the case of using Python Bindings. The details will be discussed in future parts (we mentioned at the beginning of this article). We will also elaborate on the pipeline and each step’s requirements in our next articles.
- Prepare the model and label file.
- Create the Triton configuration file.
- Create the DeepStream configuration.
- Build a custom parser.
- Run the DeepStream app.
3.2. Deploying Adaptive Learning on Jetson Devices using DeepStream and TensorRT
TensorFlow models are not computationally efficient and need relatively high memory resources to run properly. So, deploying deep learning TensorFlow models onto edge devices such as Jetson family devices with computation and memory limitations is challenging. TensorRT solves the problem by compressing the network and optimizing the operators to produce an efficient model based on your utilized hardware (Hardware-Aware Optimization).
Luckily TensorRT is supported natively with DeepStream. DeepStream provides an SDK optimized for NVIDIA Jetsons with plugins for TensorRT-based inference that supports object detection.
To deploy our model on Jetson Devices, we only need to generate a TensorRT engine of our Adaptive Learning object detection model and directly use DeepStream. This approach eliminates the need for an extra tool, such as Triton Inference Server, and its further limitations.
The steps for deploying our object detection model on Jetson are similar to the previous method (deploying on X86s). But, instead of creating a Triton config file, you need to generate a TensorRT engine using this Galliot (under the name of Neuralet) article’s instructions. Then you can use our prepared docker container, config files, and deepstream-jetson.bash script to ease the instruction. We will put detailed instructions on each step and required configurations in future articles.
4. What were the results? (Benchmark)
We have tested our Adaptive Learning model using OpenCV and DeepStream frameworks separately on Jetson Nano and X86 (using an RTX 2070 GPU). As you can see from the results in the following table, using DeepStream on both X86 and Jetson Nano has almost doubled the end-to-end performance. You can see and compare the details in the tables below.
| Model | Optimization | Framework | Platform | Number of Resources | FPS |
|---|---|---|---|---|---|
| ssd_mobilenet_v2_coco | no | Tensorflow+OpenCV | RTX 2070 | 1 | 22.5 |
| ssd_mobilenet_v2_coco | no | Deepstream | RTX 2070 | 1 | 44.5 |
| ssd_mobilenet_v2_coco | no | Deepstream | RTX 2070 | 4 | 13.1*4 |
| Model | Optimization | Framework | Platform | Number of Resources | FPS |
|---|---|---|---|---|---|
| ssd_mobilenet_v2_coco | yes, float 16 | TensorRT+OpenCV | Jetson Nano | 1 | 10.9 |
| ssd_mobilenet_v2_coco | yes, float 16 | Deepstream | Jetson Nano | 1 | 6.58*4 |
| ssd_mobilenet_v2_coco | yes, float 16 | Deepstream | Jetson Nano | 4 | 25.7 |
5. What is Coming up?
DeepStream is built on top of the Gstreamer and hence supports application development in C/C++. On the other hand, data scientists and deep learning experts widely use Python for app development. Thus, NVIDIA introduced Python Bindings to help them build high-performance AI applications using Python. There are several reference applications both in C/C++ and in Python for you to make it easier to get started with DeepStream. However, if you want to have customized modules, such as new post-processing techniques or visualization features in your pipeline, you should write C/C++ codes or use Python Bindings.
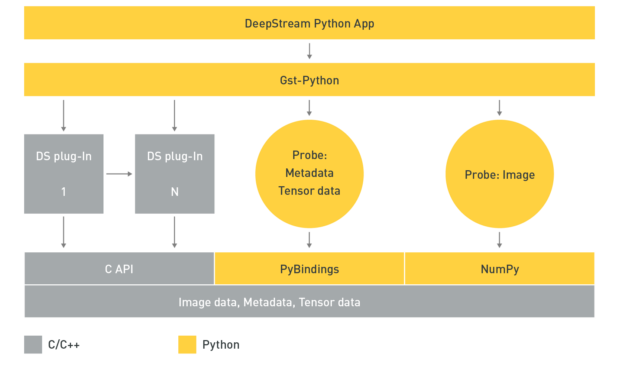
In Galliot, we have also started working with Python bindings to build more customizable models as well. First, we will try to parse and post-process our Object Detection model output using Python. Then, we aim to work on Visualization (like our Smart Social Distancing solution) by building an application that measures Social Distancing using DeepStream. We would solve this problem by building a Python plugin that uses the model’s outputs (bounding boxes) to measure the distances and assigns a color to each bounding box based on the correlated distances.
Finally, we would deploy our Pose Estimation model on DeepStream. There are three steps to be done here; we should first decide whether to export our model to a TensorRT engine for deployment or directly use Triton inference Server. After that, we need to handle the post-processing phase by creating a Python plugin. In the end, we must write the visualization codes using Python Bindings.
6. Conclusion
This article briefly described how we deployed our Adaptive Learning object Detection Model on X86s and Jetson devices using NVIDIA DeepStream and Triton Inference Server. Using DeepStream integrated with the Triton server, you can easily run your inferences on the streaming data (video) using any major framework of your choice.
We introduced a few of DeepStream’s advantages compared to other similar tools and presented a table of results extracted from our object detection model.
Suppose you are struggling with similar challenges for building high-performance Intelligent Video Analytics applications or looking for an easy tool for running inferences on streaming data. In that case, we encourage you to employ DeepStream and NVIDIA Triton Inference Server toolkits.
You are welcome to share your opinion on this topic with us using the comment section or send your suggestions using our email address, hello@galliot.us, or the contact us form.
You can visit our Adaptive Object Detection repository to reach out to the configs and other files.
Leave us a comment
Comments
Get Started
Have a question? Send us a message and we will respond as soon as possible.
Great tool for video analytics on streaming data. Nice Job